- Home
- Forum
- Big Data Platform
- Adding File to HDFS
Adding File to HDFS
we know that if we have a remote cluster we connect to it through SyncFusion Big Data Studio
and by exploring Hdfs in studio in remote cluster we will find these installed folders by syncfusion under /HDFSRoot/Data
like AdventureWorks ,NASA_Access_Log
and if we go to name node and explore files we will find that the Samples folder is equavelent to Hdfs Root
and we find these folders under folder
C:\Syncfusion\HadoopNode\3.1.0.3\Samples\Data
when we use Big Data Studio and add a folder to HDFS and let it be named TestFolder
Under The Path /HDFSRoot/Data
isn't it supposed that i should find this folder added under
C:\Syncfusion\HadoopNode\3.1.0.3\Samples\Data in name node
and what about finding this folder in data nodes
because when we add a file to hdfs it should be replicated
ihaven't tested this case before in normal hadoop cluster ,for that iam missing some concepts
thanks
SIGN IN To post a reply.
8 Replies
SH
Shadi
December 7, 2016 12:10 PM UTC
another question please Is syncFusion Beta or alpha Version
KS
Karthikeyan SankaraVadivel
Syncfusion Team
December 8, 2016 12:45 PM UTC
Hi Shadi,
Thank you for using Syncfusion BigData Platform.
Please find our response for your queries.
|
we know that if we have a remote cluster we connect to it through SyncFusion Big Data Studio
and by exploring Hdfs in studio in remote cluster we will find these installed folders by syncfusion under /HDFSRoot/Data
like AdventureWorks ,NASA_Access_Log
and if we go to name node and explore files we will find that the Samples folder is equavelent to Hdfs Root
and we find these folders under folder
C:\Syncfusion\HadoopNode\3.1.0.3\Samples\Data
|
In our BigData platform, we have shipped some samples for the Hadoop ecosystem packages which requires the sample data sets to be present in HDFS.
We have move the sample data set from the local file system (C:\Syncfusion\HadoopNode\3.1.0.3\Samples\Data) to HDFS.
HDFS is a Java-based file system that provides scalable and reliable data storage. An HDFS consist of NameNode which filesystem metadata and DataNode which used to stores the Data.
Please refer the following link,
Once we move the data to HDFS , Internally these files are split into one or more blocks and these blocks are stored in to the DataNodes.
The NameNode is responsible to keep track of the blocks stored in the DataNodes.
Please refer the following link for more details,
|
|
when we use Big Data Studio and add a folder to HDFS and let it be named TestFolder
Under The Path /HDFSRoot/Data
isn't it supposed that i should find this folder added under
C:\Syncfusion\HadoopNode\3.1.0.3\Samples\Data in name node
and what about finding this folder in data nodes
because when we add a file to hdfs it should be replicated
ihaven't tested this case before in normal hadoop cluster ,for that iam missing some concepts
|
No , we can’t able to replicate the created directory in HDFS to the local file system. Because all the files created in the HDFS are split into one or more blocks and these blocks are stored in the Data Node in the below Metadata directory .
· C:\Syncfusion\HadoopNode\3.1.0.3\Metadata\data\dfs\datanode.
Note:
· Changes in the MetaData directory may lead to data loss.
Please refer the following link,
|
|
another question please Is syncFusion Beta or alpha Version |
Syncfusion Big Data Platform is neither Alpha or Beta version. Current stable version is v3.1.0.25
|
Regards,
Karthikeyan S
SH
Shadi
December 13, 2016 08:19 AM UTC
Thanks very much for clarification
what Confused me is the similarity between hdfs files and local system files and i didnt think of Files copying From Local file
system to hdfs system
I though that syncfusion is going o handle hdfs in a different way but every thing ok
is there any difference between Hadoop in general and hadoop on syncfusion mechanisms?
what Confused me is the similarity between hdfs files and local system files and i didnt think of Files copying From Local file
system to hdfs system
I though that syncfusion is going o handle hdfs in a different way but every thing ok
is there any difference between Hadoop in general and hadoop on syncfusion mechanisms?
you mentioned that the stable version of syncfusion is v3.1.0.25
but my current version is v3.1.0.0
if i want to upgrade to this version 3.1.0.25
i should reinstall big data cluster ,big data studio and big data agent again or upgrade them
but how the cluster is going to work after big data cluster new version
because the config files refers to folder hadoopNode/3.1.0.3
for example hdfs-site file will contain this value for dfs.datanode.data.dir property
/C:/Syncfusion/HadoopNode/3.1.0.3/Metadata/data/dfs/datanode
but after cluster manager 3.1.0.25 installation this value will be wrong
and cluster will be lost ,should i edit all configuration files properties or that will be applied automatically to hadoop node when i reinstall cluster manager and connect to cluster ?
i want to verify this state before trying
SH
Shadi
December 13, 2016 08:25 AM UTC
Another question please if i want to add specific hadoop node ,i should install big data studio in this node and add hdfs on local cluster ,then it will be replicated
with replication factor but first
replica will be on this node, is this scenario ok
with replication factor but first
replica will be on this node, is this scenario ok
KS
Karthikeyan SankaraVadivel
Syncfusion Team
December 14, 2016 01:14 PM UTC
Hi Shadi,
Please find our response for your queries.
|
is there any difference between Hadoop in general and hadoop on syncfusion mechanisms?
|
Yes, we have customized Hadoop and its ecosystem to support windows environment. |
|
you mentioned that the stable version of syncfusion is v3.1.0.25
but my current version is v3.1.0.0 |
The Syncfusion Big Data Platform has stable release since v2.1.0.77.
v3.1.0.3 used by you is also a stable release.
|
|
if i want to upgrade to this version 3.1.0.25
i should reinstall big data cluster ,big data studio and big data agent again or upgrade them
but how the cluster is going to work after big data cluster new version
because the config files refers to folder hadoopNode/3.1.0.3
for example hdfs-site file will contain this value for dfs.datanode.data.dir property
/C:/Syncfusion/HadoopNode/3.1.0.3/Metadata/data/dfs/datanode
but after cluster manager 3.1.0.25 installation this value will be wrong
and cluster will be lost ,should i edit all configuration files properties or that will be applied automatically to hadoop node when i reinstall cluster manager and connect to cluster ?
i want to verify this state before trying |
You can upgrade to latest version of Cluster Manager application and Big Data Management Studio application, where the old cluster continues to run without any data loss.
To do the same please do the following steps,
Upgrade Cluster Manager Application:
Step 1:
Download latest version of Cluster manager.
Step 2:
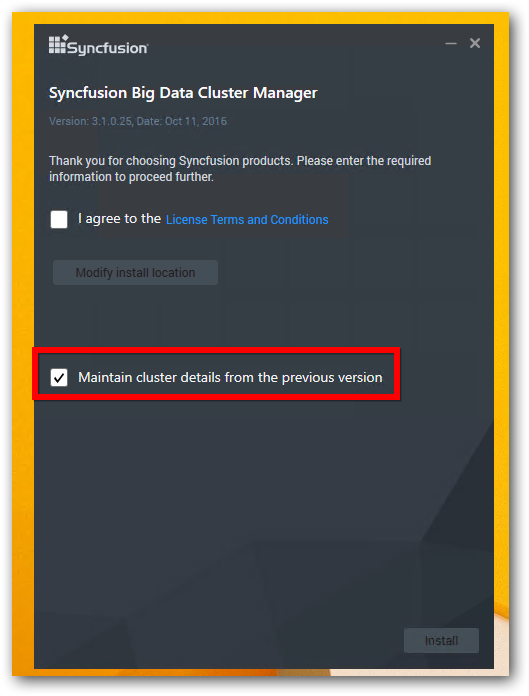
Please Check the checkbox “Maintain cluster details from the previous version” in the installation wizard and proceed.
 Upgrade Big Data Agent:
Step 1:
Download latest version of Big Data Agent.
Step 2:
Re-Install the Big Data Agent application in all nodes of the cluster.
Upgrade Big Data Studio:
Step 1:
Download latest version of Cluster manager.
Step 2:
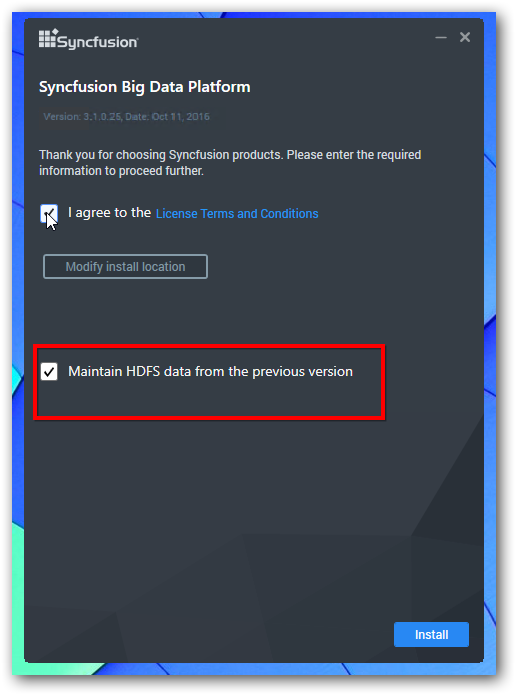
Check the checkbox “Maintain HDFS data from the previous version” in the installation wizard and proceed.
 Note:
We have enabled SSL to secure all communication from Cluster manager and Big Data Studio with Big Data agents in Syncfusion Big Data Platform v3.1.0.25.
We strongly recommend you to upgrade Cluster manager, Big Data agents and also Big Data Studio to work properly. Please refer the following link for further clarification, https://help.syncfusion.com/bigdata/migration |
|
Another question please if i want to add specific hadoop node ,i should install big data studio in this node and add hdfs on local cluster ,then it will be replicated with replication factor but first replica will be on this node, is this scenario ok |
No, we don’t require to install Big Data studio to install in to the new Hadoop Node. We can able to add the new Hadoop Node (Data Node) to the existing cluster in Cluster Manager application itself.
Once new data node is added, Hadoop will move missing replica to the new data node automatically.
Please refer the link for further clarification- https://help.syncfusion.com/bigdata/cluster-manager/cluster-management#add-data-node-in-hadoop-cluster |
Please let me know if you have any further clarifications.
Regards,
Karthikeyan S
SH
Shadi
December 18, 2016 09:46 AM UTC
thanks very much for your explanation
About the question
About the question
if i want to add specific hadoop node ,i should install big data studio in this node and add hdfs on local cluster ,then it will be replicated
with replication factor but first
replica will be on this node, is this scenario ok
with replication factor but first
replica will be on this node, is this scenario ok
I missed the word add hdfs file
what i meant is not adding new data node because you have explained the easy way to add a new data node in this link
https://help.syncfusion.com/bigdata/cluster-manager/cluster-management#add-data-node-in-hadoop-cluster
what i meant is not adding new data node because you have explained the easy way to add a new data node in this link
https://help.syncfusion.com/bigdata/cluster-manager/cluster-management#add-data-node-in-hadoop-cluster
what i meant was we know that when we can connect to a cluster by applying it's name node ip in add cluster button in big data studio
and exploring hdfs will explore hdfs files that are replicated in data nodes
but if we want to explore the hdfs that belongs to specific data node
we can install big data studio on that node and explore hdfs
which will view the replicated files in cluster if this data node has a replica of and it's special hdfs files if
the replication factor was 1 when inserting data from this datanode
isn't it
which will view the replicated files in cluster if this data node has a replica of and it's special hdfs files if
the replication factor was 1 when inserting data from this datanode
isn't it
Does installing big data studio in data node affects any cluster configuration ?
DK
Dinesh Kumar P
Syncfusion Team
December 19, 2016 01:14 PM UTC
Hi Shadi,
We considered this “Unability to start services on Hadoop Nodes” as a custom query and a support incident has been created under your account to track the status of this requirement. Please log on to our support website to check for further updates.
https://www.syncfusion.com/account/login?ReturnUrl=/support/directtrac/incidents
Regards,
Dinesh Kumar P
We considered this “Unability to start services on Hadoop Nodes” as a custom query and a support incident has been created under your account to track the status of this requirement. Please log on to our support website to check for further updates.
https://www.syncfusion.com/account/login?ReturnUrl=/support/directtrac/incidents
Regards,
Dinesh Kumar P
DK
Dinesh Kumar P
Syncfusion Team
December 19, 2016 01:26 PM UTC
Hi Shadi,
Please ignore my previous update.
|
Query |
Response |
|
if i want to add specific hadoop node ,i should install big data studio in this node and add hdfs on local cluster ,then it will be replicated
with replication factor but first
replica will be on this node, is this scenario ok
I missed the word add hdfs file |
We cannot explore or add HDFS files to specific Data Node in a multi node cluster using Big Data Studio. The distribution of blocks of files across Data Nodes will be decided by Name Node.
Internally these files are split into one or more blocks and these blocks are stored in to the DataNodes. The NameNode is responsible to keep track of the blocks stored in the DataNodes.
Please refer the following link for more details,
Note:
Adding HDFS files to specific Data Node is not recommended one, but it can be done by source code level change, to know more please check the below code,
Could you please share your use case for this requirement so that we will check and let you know the appropriate recommendations? |
|
Does installing big data studio in data node affects any cluster configuration ? |
In a machine where Big Data Agent is installed, Big Data Studio cannot be installed for the following reasons,
- As this node is a part of a cluster, already some Hadoop services related to that cluster will be in running state. Installing Big Data Studio in the same machine would create a standalone cluster and the previously running cluster’s Hadoop services will get stopped.
- Big Data Studio has an in-built agent to manage its stand-alone cluster. So, installing Big Data Studio will over write the currently running Big Data Agent. |
|
what i meant was we know that when we can connect to a cluster by applying it's name node ip in add cluster button in big data studio
and exploring hdfs will explore hdfs files that are replicated in data nodes
but if we want to explore the hdfs that belongs to specific data node
we can install big data studio on that node and explore hdfs
which will view the replicated files in cluster if this data node has a replica of and it's special hdfs files if
the replication factor was 1 when inserting data from this datanode
isn't it |
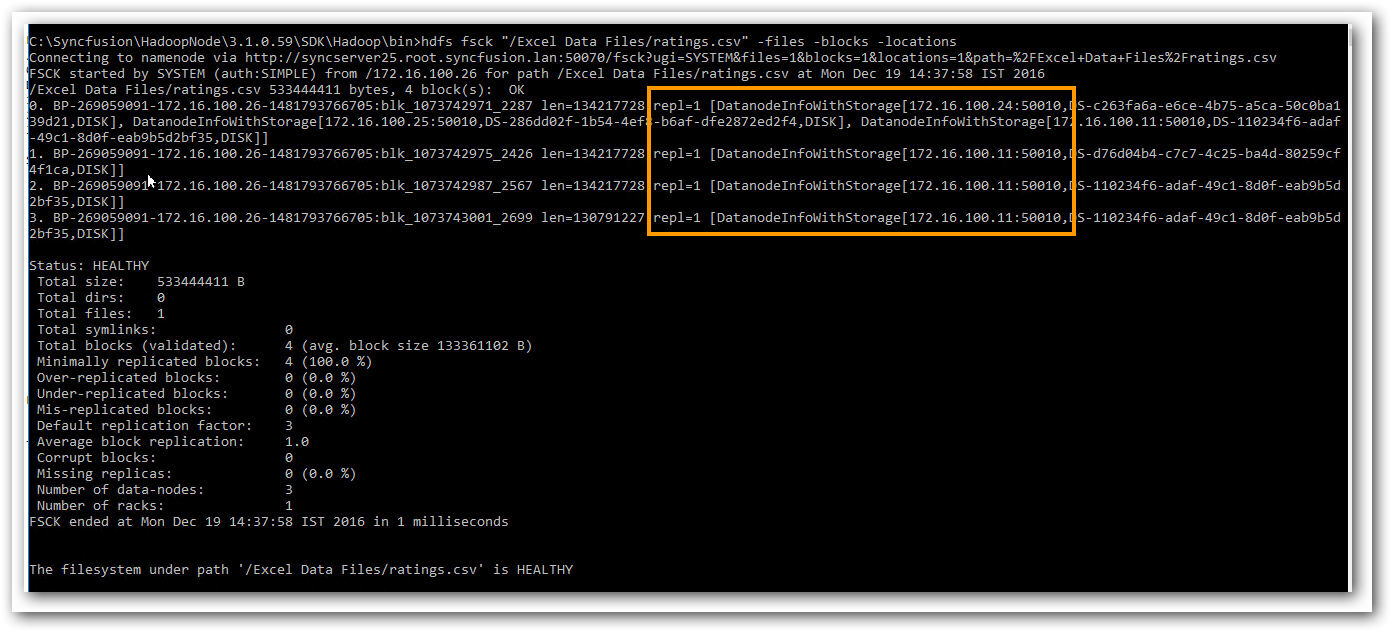
When multiple data nodes exist and the replication factor is 1, data may not be saved in 1 single node always. For example, with 3 data nodes uploading a file of 508 MB in size, it gets stored in a distributed manner as part files in different nodes. The following FSCK report details the same,
 |
Please let us know in case of further queries,
Thanks,
Dinesh Kumar P
SIGN IN To post a reply.
- 8 Replies
- 3 Participants
-
SH Shadi
- Dec 7, 2016 11:45 AM UTC
- Dec 19, 2016 01:26 PM UTC
