OCR Library for PDF and Images in C#
- Recognize text from scanned PDF documents.
- Extract text from images.
- Save OCR results as text, structured data, or searchable PDF documents.
No credit card required.
Explore ExamplesNo credit card required.

Trusted by the world’s leading companies
Overview
The Syncfusion .NET Optical Character Recognition (OCR) library is used to extract text from scanned PDFs and images. With just a few lines of C# code, a scanned PDF document containing a raster image is converted into a searchable and selectable PDF document. Users can save the OCR result as text, structured data, or searchable PDF documents. The .NET OCR library uses the powerful Tesseract OCR engine.
The OCR feature works seamlessly across platforms, including Windows, macOS, and Linux, through any .NET-based applications, such as ASP.NET Core, ASP.NET MVC, Blazor, WinForms, WPF, and WinUI.
Convert scanned PDF to a searchable PDF in C#
The below code demonstrates how to convert scanned PDF to a searchable PDF.
Key features of the OCR library
Discover the features of our OCR processor library to enhance text extraction, language recognition, and document processing for seamless integration.
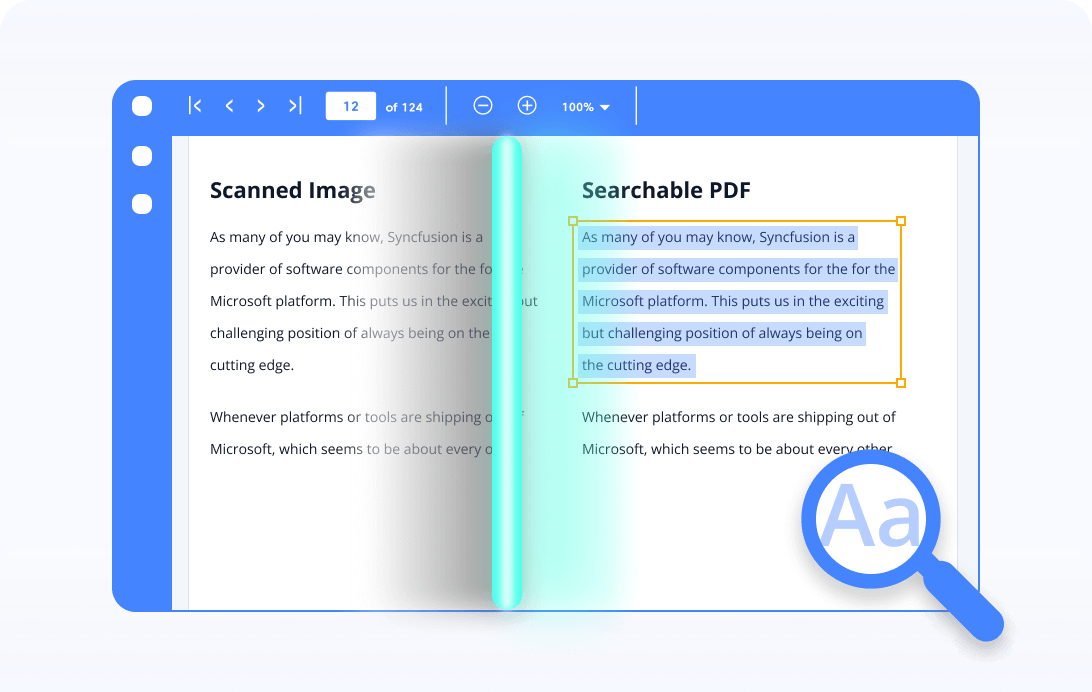
Create a searchable PDF
Perform OCR on an entire scanned PDF document and convert it into a searchable PDF document.
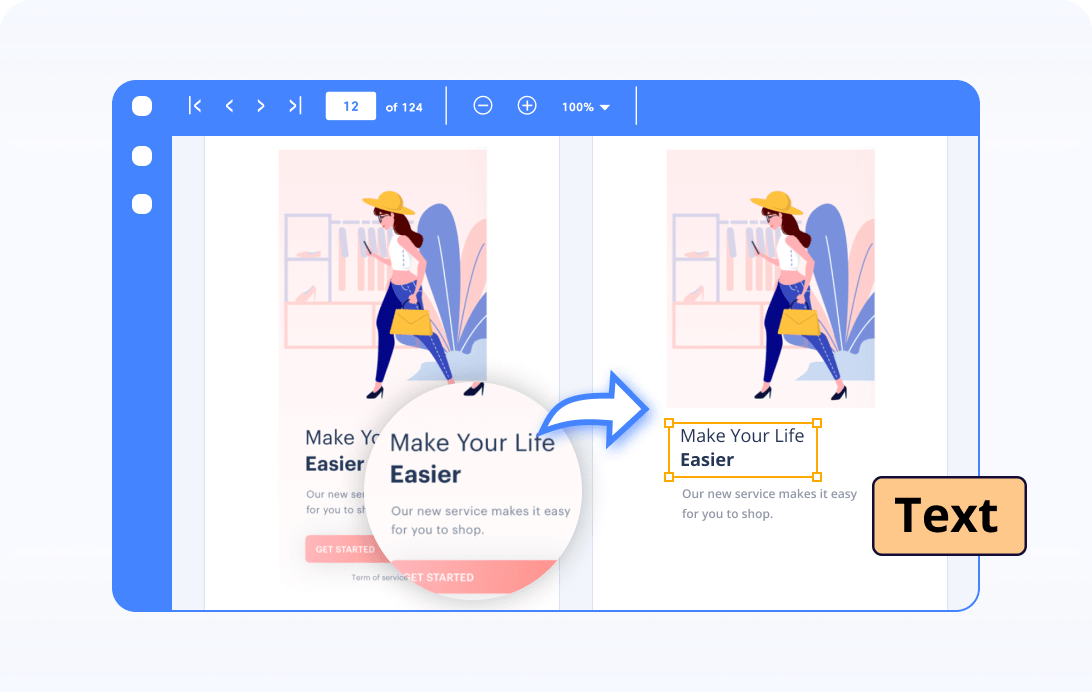
Extract text from an image
Extract text from a single scanned image or multi-page TIFF images.

Perform OCR on a rotated page
Extract the text from a scanned, rotated page of a PDF document and convert it to a searchable PDF document.
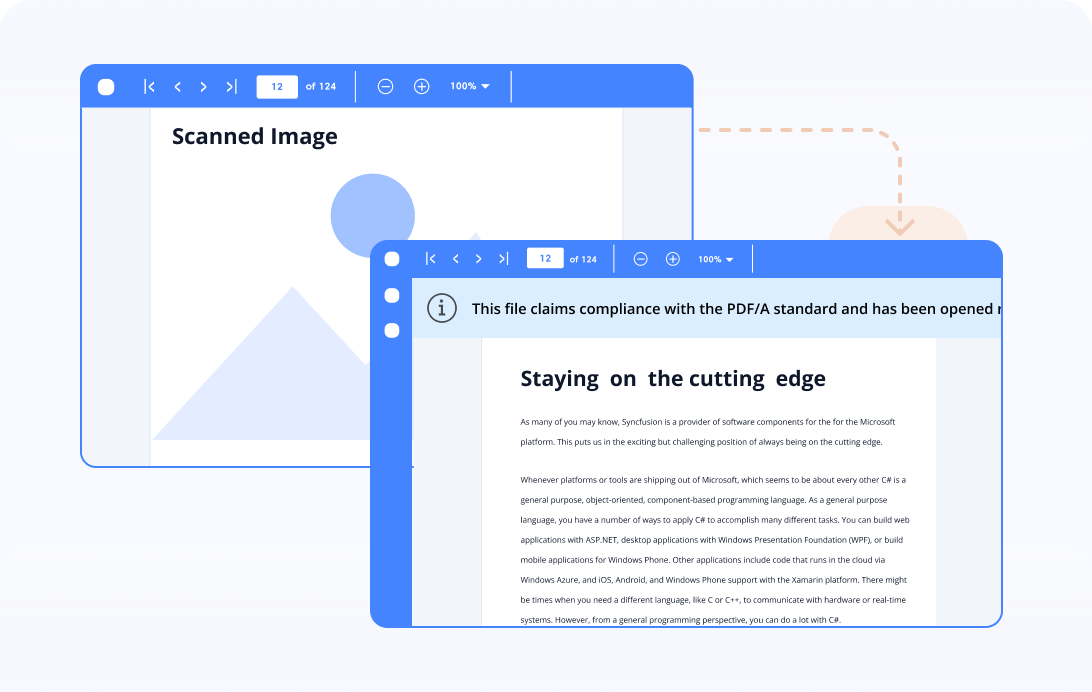
Convert image to searchable PDF/A
Make images searchable and selectable by converting them to PDF or PDF/A document using OCR.

Advanced image preprocessing
Enhance the accuracy of OCR by applying advanced preprocessing techniques, such as grayscale conversion, deskewing, noise removal, contrast adjustment, and image binarization. These optimizations generate cleaner input images for significantly improved text recognition results.

Multilanguage recognition
Automatically extract text from documents containing content in multiple languages. The Syncfusion OCR engine supports recognizing and processing multilingual text within the same PDF or image seamlessly, ensuring accurate results for global and mixed-language documents.
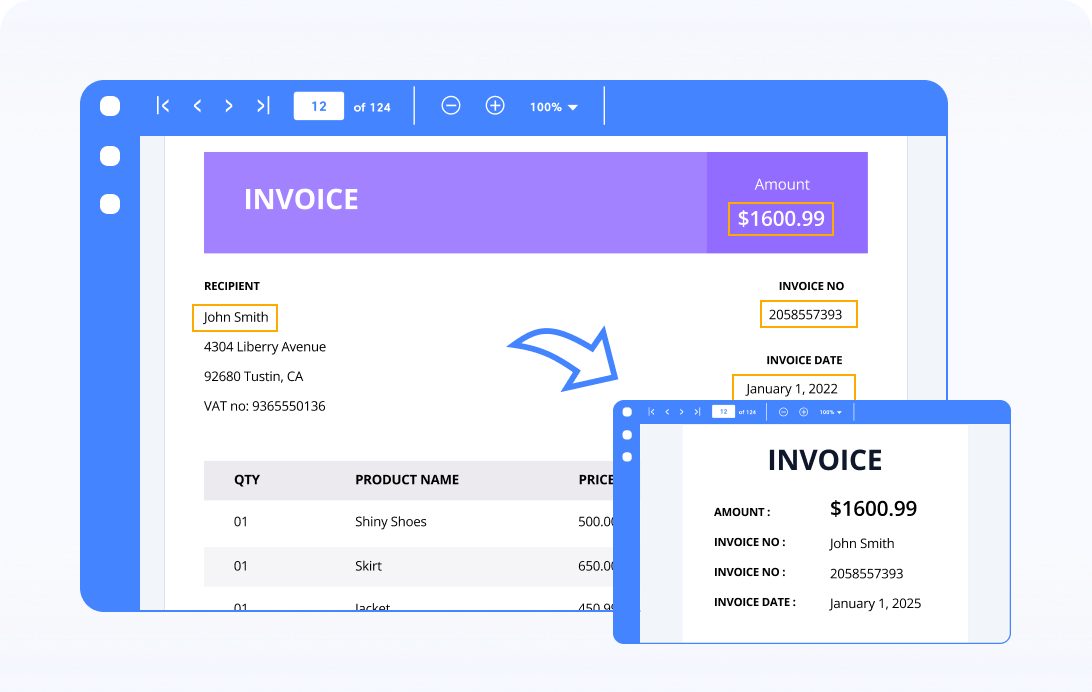
Zonal text extraction
Extract data from PDFs and images by restricting OCR to a particular region in a PDF or image.
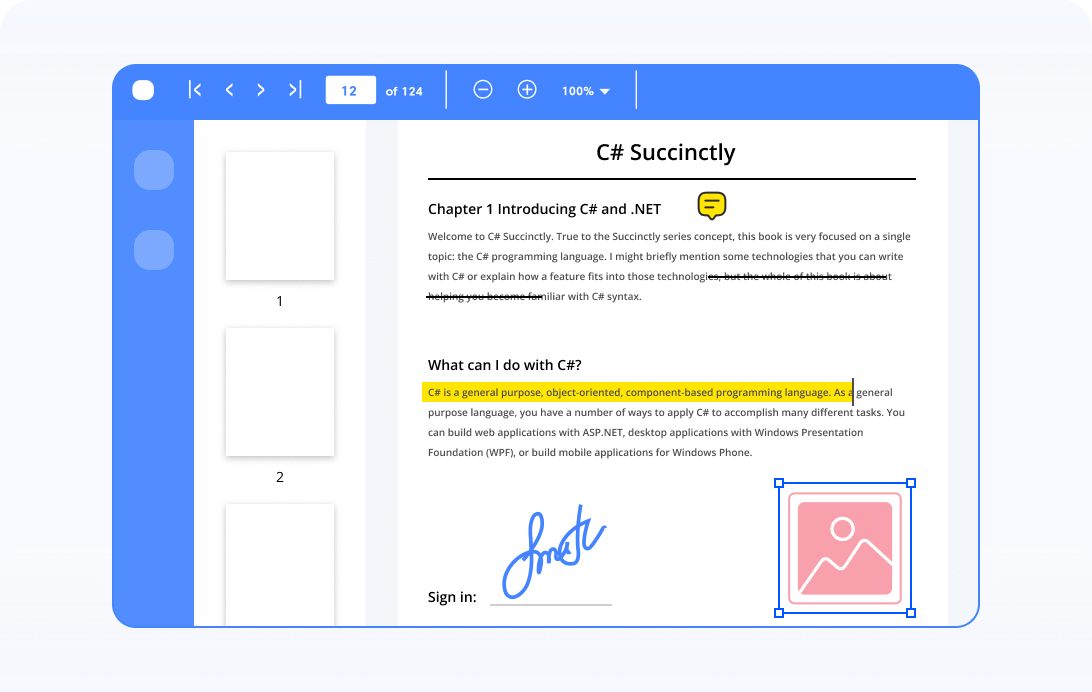
Post-processing
After performing OCR, you can programmatically highlight, underline, and strike through the text of the resulting PDF document. You can also redact, edit, and digitally sign the PDF document.
Explore references for the .NET OCR library
Discover valuable resources from our blog and knowledge base on using the OCR library.



Explore these resources for comprehensive guides, knowledge base articles, insightful blogs, and ebooks.




Product Updates

Technical Support




Frequently Asked Questions
What is OCR?
OCR stands for optical character recognition. It is a technology used to convert different types of documents, such as scanned paper documents, PDF files, or images captured by a digital camera, into editable and searchable data.
What types of documents can OCR process?
OCR can process various types of documents, including scanned paper documents, PDF files, images, screenshots, and photographs containing printed or handwritten text.
How does OCR work for PDF and images?
The OCR library analyzes the shapes, patterns, and structures within an image or PDF file to identify and extract text. It then converts this extracted text into a format that can be edited, searched, and manipulated.
What are the benefits of using OCR on PDF documents and images?
OCR lets you convert non-editable documents, such as scanned images or PDF files, into editable and searchable formats. This allows for easier document management, text extraction, content indexing, and accessibility improvements.
Our Customers Love Us




See Real Success Stories
Developers around the world trust Syncfusion’s Essential Studio to simplify complex projects and speed up delivery. With a vast library of UI controls, powerful SDKs, and reliable support, Essential Studio helps teams build enterprise-ready applications with confidence.
Read Our Customer StoriesIndustry
Software development
75% Cost reduction
50% Faster development
Industry
Utilities (oil and gas)
450+ hours saved
Streamlined processes and hours of development effort saved.
Advanced, flexible features
Empowered users through robust and versatile functionality.
Industry
Software and technology
1000+ of hours saved
Accelerated development with enterprise-ready UI components.
Efficient file management
Streamlined workflows with document libraries without building them from scratch.
Industry
Software and technology
2 Years of delay avoided
Two years of delays prevented with proactive planning.
On-time delivery
Projects delivered on schedule using trusted controls.
Industry
IT services and IT consulting
Improved performance
Large datasets handled with easy customization and quick debugging.
Highly customizable
Plug-and-play controls with quick template integration.
Industry
Professional services
Instant access
Quick availability of features and resources.
Reduced dependencies
Fewer dependencies for faster development.
Rated by users across the globe
Want to create, view, and edit PDF files in C# or VB.NET?
No credit card required.

Awards
Greatness—it’s one thing to say you have it, but it means more when others recognize it. Syncfusion® is proud to hold the following industry awards.

