
Optical character recognition (OCR) technology plays a vital role in transforming printed or handwritten text into editable and searchable digital content. With the advancements in OCR algorithms, extracting information from PDFs, images, and scanned documents has become more accurate and efficient.
In this blog, we’ll explore how the Syncfusion PDF Library simplifies the process of implementing OCR in your apps, making it easy to extract text and data from scanned documents, images, and PDF documents.
What is optical character recognition (OCR)?
Optical Character Recognition (OCR) is a technology used to convert scanned paper documents in the form of PDF files or images into searchable and editable data. This technology uses advanced algorithms to recognize characters, symbols, and patterns within an image and then translates them into machine-encoded text.
The Syncfusion OCR processor library has extended support to process OCR on scanned PDF documents and images with the help of Google’s Tesseract Optical Character Recognition engine.
Tesseract engine
Tesseract is an open-source optical character recognition (OCR) engine. It is one of the most widely used OCR engines in the world and is known for its high accuracy and versatility.
Note: The starting supported version of Tesseract in ASP.NET Core is 4.0.
Why Choose the Syncfusion PDF Library for OCR?
The Syncfusion PDF Library is a robust and feature-rich tool that provides developers with a seamless way to integrate OCR capabilities into their apps. Here are some key reasons why Syncfusion stands out:
- High accuracy: The Syncfusion PDF Library uses the Tesseract OCR engine, renowned for being one of the most accurate OCR engines available. As a result, the library achieves remarkably high accuracy when extracting text from diverse sources, including challenging inputs like low-resolution scans or intricate images.
- Multiple language support: The library supports a wide range of languages, making it suitable for apps that require multilingual OCR capabilities. The dictionary packs for the languages can be downloaded from this GitHub repository.
- Cross-platform compatibility: The Syncfusion OCR processor library works seamlessly in various platforms: Azure App Services, Azure Functions, AWS Textract, Docker, WinForms, WPF, Blazor, ASP.NET MVC, ASP.NET Core with Windows, MacOS, and Linux.
In this blog, we’ll delve into the capabilities of the Syncfusion OCR processor library, enabling users to harness the power of OCR. The article will cover the following topics:
- OCR for an entire scanned paper document
- OCR for a region of a scanned PDF document
- OCR for an image and convert it to a PDF document
- OCR for a rotated page of a PDF document
- Get OCRed text and bounds from scanned PDF document
- Perform OCR with Unicode characters
Getting started with app creation
- First, we need to create a .NET console app using Visual Studio.
- Then, open the Package Manager Console from Tools -> NuGet package Manager -> Package Manager Console.
- Execute the following command to install the Syncfusion.PDF.OCR.Net.Core NuGet package.
Install-Package Syncfusion.PDF.OCR.Net.Core
OCR for an entire scanned paper document
Leveraging our library, you can transform a complete scanned PDF document into a searchable PDF. This enables quick and efficient access to the extracted textual content.
Follow these steps to perform OCR on an entire scanned PDF document using our .NET PDF Library:
- First, create an instance of the OCRProcessor class to initiate the OCR process.
- Load the desired PDF document using the PdfLoadedDocument class.
- Specify the OCR language using the OCRSettings class.
- Execute OCR on the input document using the PerformOCR method.
- Finally, save the processed PDF document into a memory stream using the Save method.
The following code example shows how to convert an entire scanned PDF into a searchable PDF document.
//Initialize the OCR processor.
using (OCRProcessor processor = new OCRProcessor())
{
//Load an existing PDF document.
FileStream inputPDFstream = new FileStream("Input.pdf", FileMode.Open);
PdfLoadedDocument document = new PdfLoadedDocument(inputPDFstream);
//Set OCR language.
processor.Settings.Language = "lat";
//Perform OCR with input document.
processor.PerformOCR(document, "Tessdata/");
//Create file stream.
using (FileStream outputFileStream = new FileStream("Output.pdf", FileMode.Create, FileAccess.ReadWrite))
{
//Save the PDF document to file stream.
document.Save(outputFileStream);
}
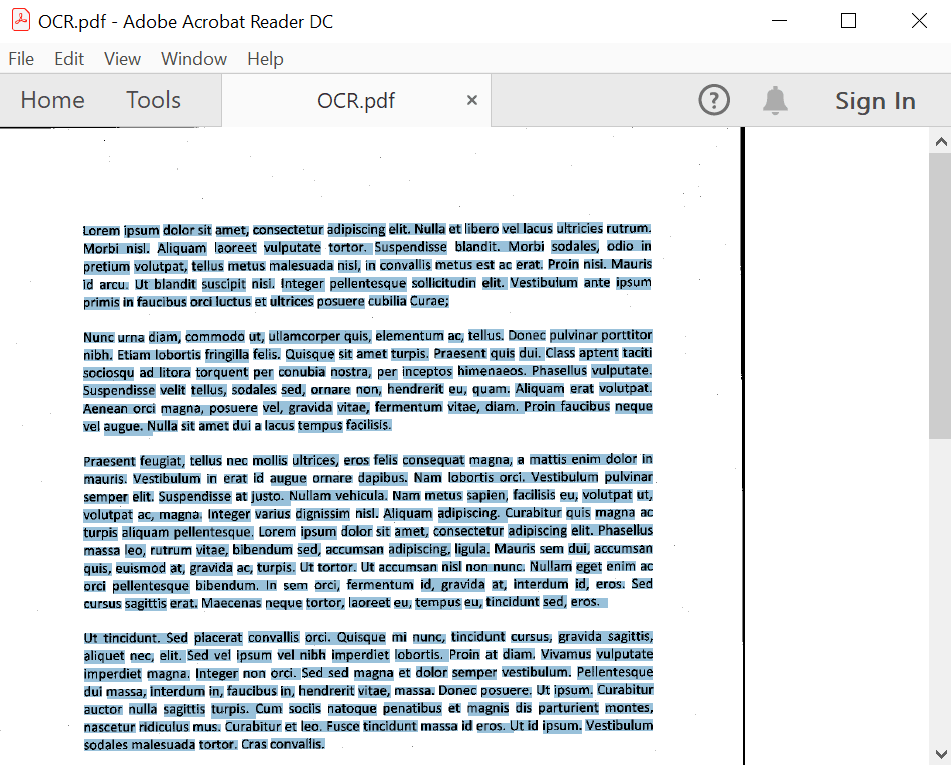
}By executing this code example, you will get a PDF document like in the following screenshot.
OCR for a region of the scanned PDF document
Our .NET PDF Library lets you perform OCR on specific regions or multiple regions of a scanned PDF document.
Follow these steps to perform OCR for a region of the scanned PDF document:
- Create the OCRProcessor class to begin the OCR process.
- Load the required PDF document using the PdfLoadedDocument class.
- Specify the OCR language using the OCRSettings class.
- Create a PageRegion object to define the specific region(s) of the document that need OCR.
- Set the properties of the page index and page regions using the PageIndex and PageRegions properties, respectively.
- Add the defined region(s) to a PDF document’s page regions using the Add method.
- Assign the page regions to the Regions property of the OCRSettings class.
- Execute OCR on the input document using the PerformOCR method.
- Save the processed PDF document to the memory stream using the Save method.
The following code example shows how to convert a region in a scanned PDF into a searchable PDF document.
//Initialize the OCR processor.
using (OCRProcessor processor = new OCRProcessor())
{
//Load a PDF document.
FileStream inputPDFStream = new FileStream("Input.pdf", FileMode.Open);
PdfLoadedDocument loadedDocument = new PdfLoadedDocument(inputPDFStream);
//Set OCR language to process.
processor.Settings.Language = "lat";
RectangleF rectangle = new RectangleF(0, 100, 950, 150);
//Assign rectangles to the page.
List>PageRegion> pageRegions = new List>PageRegion>();
PageRegion region = new PageRegion();
region.PageIndex = 0;
region.PageRegions = new RectangleF[] { rectangle };
pageRegions.Add(region);
processor.Settings.Regions = pageRegions;
//Process OCR by providing the PDF document.
processor.PerformOCR(loadedDocument, "Tessdata/");
//Create file stream.
using (FileStream outputFileStream = new FileStream("Output.pdf", FileMode.Create, FileAccess.ReadWrite))
{
//Save the PDF document to file stream.
loadedDocument.Save(outputFileStream);
}
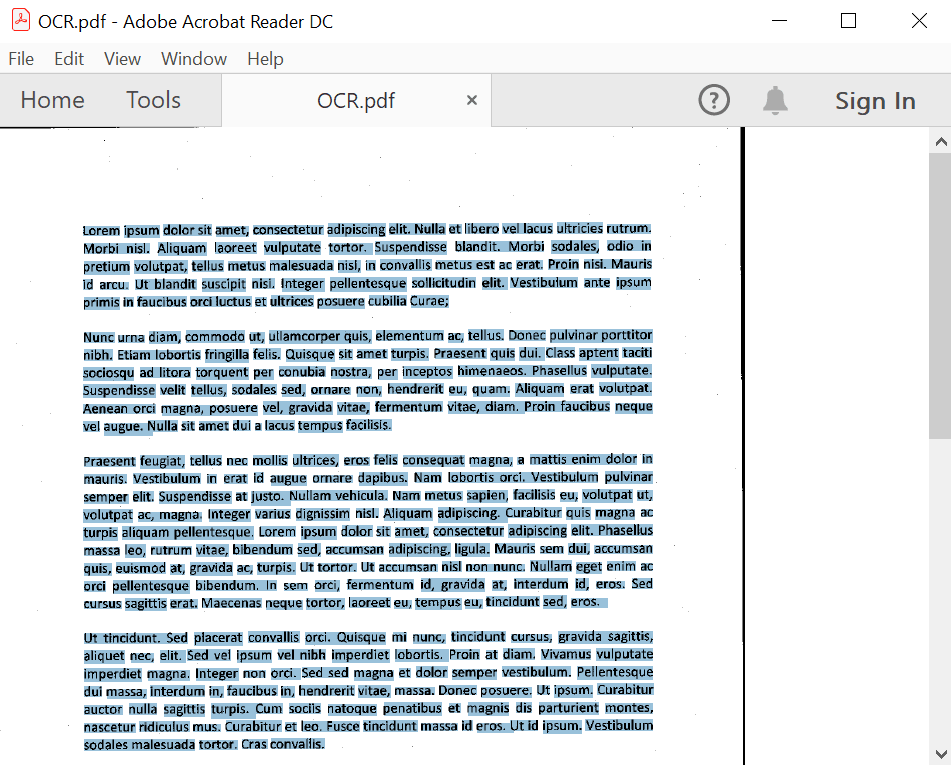
}By executing this code example, you will get a PDF document like in the following screenshot.

OCR on image and converting it to a PDF document
You can transform any scanned image into a searchable and selectable PDF document. Follow these steps to perform OCR on a scanned image and convert it into a searchable PDF:
- Instantiate the OCRProcessor class to begin the OCR process.
- Load the image from a local file using the FileStream class.
- Specify the OCR language using the OCRSettings class.
- Execute OCR by providing the bitmap image using the PerformOCR method, and the result will generate a PDF document.
- Save the generated PDF document to the memory stream using the Save method.
Following is the code example demonstrating how to convert a scanned image into a searchable and selectable PDF document.
//Initialize the OCR processor.
using (OCRProcessor processor = new OCRProcessor())
{
//Get stream from an image file.
FileStream imageStream = new FileStream(@"Input.jpg", FileMode.Open);
//Set OCR language to process.
processor.Settings.Language = Languages.English;
//Process OCR by providing the bitmap image.
PdfDocument document = processor.PerformOCR(imageStream);
//Create file stream.
using (FileStream outputFileStream = new FileStream(@"Output.pdf", FileMode.Create, FileAccess.ReadWrite))
{
//Save the PDF document to file stream.
document.Save(outputFileStream);
}
}By executing this code example, you will get a PDF document like in the following screenshot.
OCR for a rotated page of a PDF document
Follow these steps to get the text from a rotated page of a PDF document:
- Create an instance of the OCRProcessor class to initiate the OCR process.
- Load the desired PDF document using the PdfLoadedDocument class.
- Specify the OCR language using the OCRSettings class.
- Use the PageSegment property and set its value to AutoOsd through the PageSegmentMode enum. This will enable automatic optical character recognition for the entire page.
- Execute OCR on the input document using the PerformOCR method.
- Save the processed PDF document to a memory stream using the Save method.
Refer to the following code example to perform OCR on an alternated PDF document.
//Initialize the OCR processor.
using (OCRProcessor processor = new OCRProcessor())
{
//Load an existing PDF document.
FileStream stream = new FileStream("Input.pdf", FileMode.Open);
PdfLoadedDocument document = new PdfLoadedDocument(stream);
//Set OCR language.
processor.Settings.Language = "lat";
//Set OCR page auto detection rotation.
processor.Settings.PageSegment = PageSegMode.AutoOsd;
//Perform OCR with input document and tessdata (Language packs).
string extractedText = processor.PerformOCR(document, "Tessdata/");
//Writes the text to the file.
File.WriteAllText("OCR.txt", extractedText);
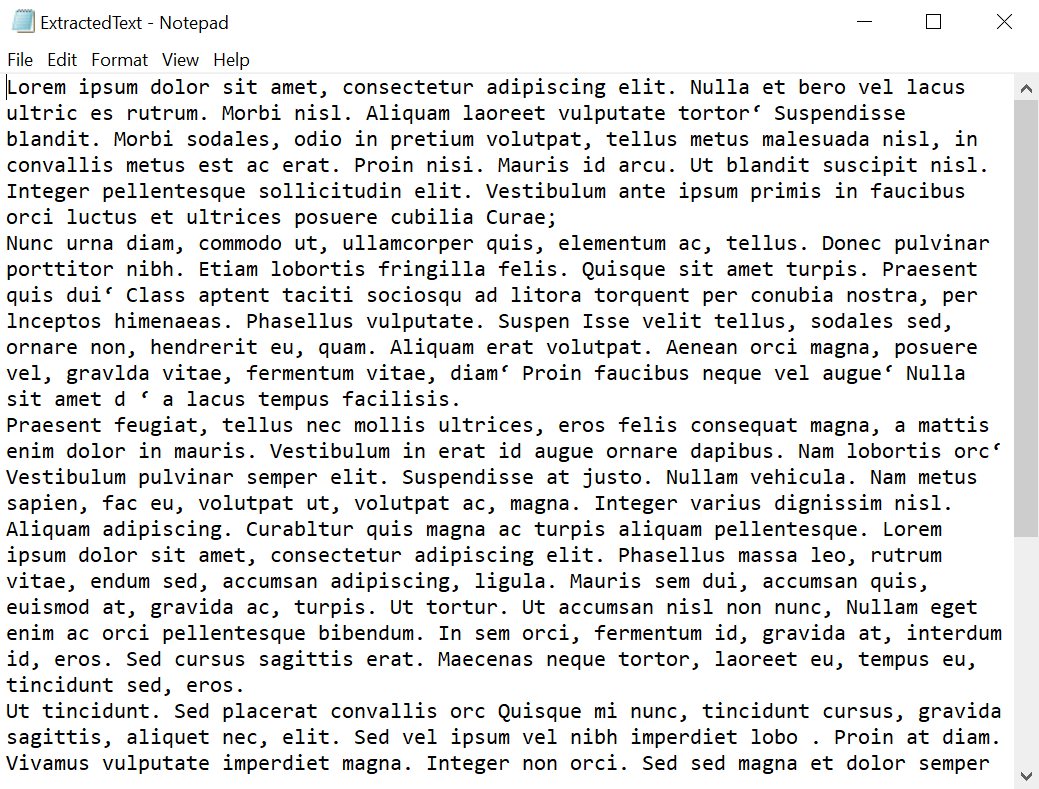
}By executing this code example, you will get a PDF document like in the following screenshot.
Get text and bounds from scanned PDF document
You can also easily obtain text and its corresponding bounds from a scanned PDF document. Follow these steps to achieve this functionality:
- Create an instance of the OCRProcessor class to initiate the OCR process.
- Load the desired PDF document using the PdfLoadedDocument class.
- Specify the OCR language using the OCRSettings class.
- Create a layout using the OCRLayoutResult class to capture OCR data and layout information.
- Execute OCR on the input document using the PerformOCR method.
- Obtain the line collection from the first page using the OCRLineCollection class.
- Access each line and its respective bounds using the Line class to retrieve accurate text and positional information.
The following code example explains how to retrieve text and its bounds from a scanned PDF document with OCR.
//Initialize the OCR processor.
using (OCRProcessor processor = new OCRProcessor())
{
//Load an existing PDF document.
FileStream stream = new FileStream("Input.pdf", FileMode.Open);
PdfLoadedDocument document = new PdfLoadedDocument(stream);
//Set OCR language.
processor.Settings.Language = "lat";
//Create the layout result.
OCRLayoutResult layoutResult = new OCRLayoutResult();
//Perform OCR with input document and tessdata (Language packs).
processor.PerformOCR(document, @"Tessdata/", out layoutResult);
//Get line collection from first page.
OCRLineCollection lines = layoutResult.Pages[0].Lines;
//Get each line and its bounds.
foreach (Line line in lines)
{
string text = line.Text;
RectangleF bounds = line.Rectangle;
}
//Close the document.
document.Close(true);
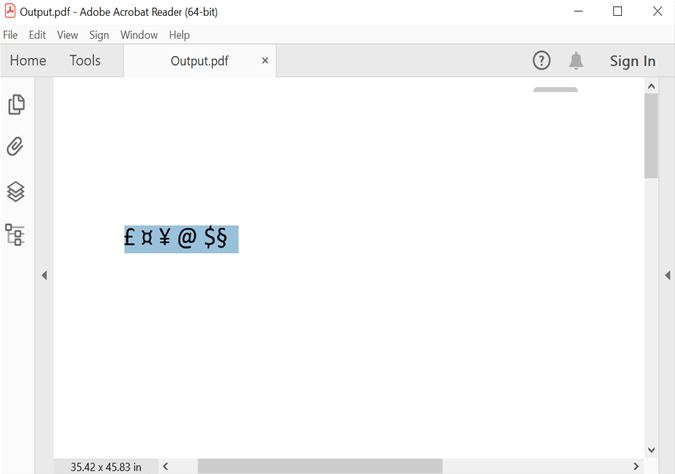
}Perform OCR with Unicode characters
Follow these steps to execute OCR on images containing Unicode characters:
- Create an instance of the OCRProcessor class to initiate the OCR process.
- Load the desired PDF document using the PdfLoadedDocument class.
- Specify the OCR language using the OCRSettings class.
- Preserve the Unicode characters in a PDF document using the UnicodeFont property.
- Execute OCR on the input document using the PerformOCR method.
- Save the processed PDF document to a memory stream using the Save method.
The following code example demonstrates how to perform OCR with Unicode characters in an image file.
//Initialize the OCR processor by providing the path of tesseract.
using (OCRProcessor processor = new OCRProcessor())
{
//Get stream from an existing PDF document.
FileStream stream = new FileStream(Path.GetFullPath(@"UnicodePDF.pdf"), FileMode.Open);
//Load the PDF document.
PdfLoadedDocument loadedDocument = new PdfLoadedDocument(stream);
//Sets Unicode font to preserve the Unicode characters in a PDF document.
FileStream fontStream = new FileStream(Path.GetFullPath(@"ARIALUNI.ttf"), FileMode.Open);
//Set the font for unicode text.
processor.UnicodeFont = new PdfTrueTypeFont(fontStream, 8);
//Set OCR language to process
processor.Settings.Language = Languages.English;
//Perform OCR by providing the PDF document.
string ocrText = processor.PerformOCR(loadedDocument);
//Create file stream.
using (FileStream outputFileStream = new FileStream(Path.GetFullPath(@"Output.pdf"), FileMode.Create, FileAccess.ReadWrite))
{
//Save the PDF document to file stream.
loadedDocument.Save(outputFileStream);
}
}By executing this code example, you will get a PDF document like in the following screenshot.
GitHub reference
You can find the examples for all these OCR options in this GitHub repository.
Conclusion
Thanks for reading! In this blog, we’ve seen how easy it is to perform OCR on PDF documents using the Syncfusion .NET PDF Library using C#. With this, you can easily extract text from scanned PDF documents and images. The library also supports a variety of languages, so you can extract text from documents in several languages.
Take a moment to peruse our documentation, where you’ll find other options and features, all with accompanying code examples.
For current Syncfusion customers, the newest version of Essential Studio® is available from the license and downloads page. If you are not a customer, try our 30-day free trial to check out these new features.
If you have any questions about these features, please let us know in the comments below. You can also contact us through our support forum, support portal, or feedback portal. We are always happy to assist you!
 No spam, just valuable updates.
No spam, just valuable updates.
Comments (1)
Awesome. Thanks