- Home
- Forum
- ASP.NET Web Forms
- Issue with Text Extraction With Bounds Using File Formats - PDF
Issue with Text Extraction With Bounds Using File Formats - PDF
I need to find certain phrases in a PDF document and am using syncfusions File Formats PDF to do so.
I follow https://help.syncfusion.com/file-formats/pdf/working-with-text-extraction?cs-save-lang=1&cs-lang=xamarin#text-extraction-with-bounds in order to extract all the words in the document with it's bound information. I will be overwriting the words I find with a form textbox to all one to edit the field.
To that end, I wrote text in the PDF such as "$T$:California" where I expect the word to be (without quotes) "$T$:California" where I split on the : and the left of the colon is $T$ which means place a textbox here and on the right of the colon is the value I want to put in the textbox. I wrote the code to do this and it works.....sometimes.
The List<TextWord> contains records where the text is not always the word I'm looking for. I search the list using textWordList.FirstOrDefault(w => w.Contains("$T$:")). The word can be on it's own line or next to text and sometimes the array will come out like ["$T"] ["$"] [":"] ["California"] or ["$T$"] [":California"] and other variations. When it comes out like ["$T$:California"] everything works.
Why does this not always pick up words that are connected without spaces? Is there a way I can reliably find my words in the List<TextWord>? What causes the words to split? Is there any other way I can get the location of a word and turn it into an editable box filling in the value with the value attached to the word?
SIGN IN To post a reply.
22 Replies
AS
Aravindh Sathiyamoorthy
Syncfusion Team
September 4, 2019 05:19 PM UTC
Hi Joe,
Thank you for contacting Syncfusion support.
We are working on this issue and we will update further details on 5th September 2019.
Regards,
Aravindh Sathiyamoorthy.
Aravindh Sathiyamoorthy.
GR
Gayathri Ramalingam
Syncfusion Team
September 5, 2019 10:02 AM UTC
Hi Joe,
Thank you for your patience.
We have tried to reproduce the issue “Text is not extracted properly while performing Extract text”, but it is working fine as expected. Kindly refer the sample in the below link which we created to reproduce the reported issue.
Kindly share the following details to analyze more on this issue and it will be helpful for us to provide solution at the earliest.
1. Modify / Simple sample with which the issue could be reproduced.
2. Replication procedure to reproduce the issue or screen shot illustrating the issue.
3. PDF document with which the issue could be reproduced.
4. Syncfusion.Xamarin.Pdf version.
With Regards,
Gayathri R
Hi Joe,Thank you for your patience.We have tried to reproduce the issue “Text is not extracted properly while performing Extract text”, but it is working fine as expected. Kindly refer the sample in the below link which we created to reproduce the reported issue.Kindly share the following details to analyze more on this issue and it will be helpful for us to provide solution at the earliest.1. Modify / Simple sample with which the issue could be reproduced.2. Replication procedure to reproduce the issue or screen shot illustrating the issue.3. PDF document with which the issue could be reproduced.4. Syncfusion.Xamarin.Pdf version.With Regards,Gayathri R
Hey,
Your sample is for Xamarin. We are not doing this in Xamarin, we are doing this in a class library to be used on an asp.net server. We are using Syncfusion.Pdf.AspNet v16.4.0.52 from nuget. This also brought in Syncfusion.Compression.Base and Syncfusion.Licensing.
I've attached a quick code sample that I made up. It's a class document with a single unit test. If you run the unit test, it should load the PDF in the tests project and attempt to make text boxes around the $T$: words. The first box should be empty, the second should be prefilled with John Smith, and the third should be prefilled with Smith. You'll notice it only finds $T$: and nothing else. I couldn't get it to give me the whole word this time, as I mentioned in the original posts, on some documents it is the whole word and others it doesn't. This is an example of when it doesn't find it which is the main case we need to solve.
If you put a breakpoint at the line 64 in the TextExtractClass.cs you can check the page_text and see that array slots 24 and 25 are $T$: in 24 and 25 is John__Smith.
You'll have to build first I believe to download the nuget packages.
Attachment: SyncfusionTextExtractSample_19383b0.zip
AA
Akshaya Arivoli
Syncfusion Team
September 10, 2019 01:39 PM UTC
Hi Joe,
We have analyzed the provided sample, in that as you mentioned “$T$:” is surrounded by text boxes. Can you please confirm us whether your requirement is to surround the “$T$:” by text box or the text next to the “$T$:” should be surrounded by text box and the text next to the “$T$:” should be replaced in the text boxes. Also can you please provide more details about your requirement, use case scenario and the video demonstrating your requirement. These details will be helpful for us to investigate further on your issue and assist you better.
We have shared the output which we got from the provided sample in the below link.
Please try this and let us know if you have any concerns on this.
Regards,
Akshaya
JO
Joe
September 10, 2019 04:01 PM UTC
It is like when you say "the text next to the “$T$:” should be surrounded by text box and the text next to the “$T$:” should be replaced in the text boxes." I was the text that is to the right of the : to be the value inside of the text box. So the first text box is short and blank. The second covers the whole $T$:John__Smith area and the text box is prefilled with John Smith. Same for the last one except it is just Smith.
The purpose of this is we generate server side reports using Crystal Reports in PDF format. They do not have the ability to make the PDF editable. We wanted to make crystal reports output some type of text with the value appended and then we would use your PDF object to find the text and convert them into editable fields with the value prefilled. There are thousands of these that can be run and all have dynamic data based on our software so we can't do it by hand, we would need something that can read the PDF after its creation and then make fields editable and prefill them with the information that was already there.
As you can see from the example, I've used the similar technique for radio buttons, check boxes, and signature fields. For radio buttons and signature fields I don't have anything after : but for check boxes it is something like this: $C: or $C:false is an unchecked box and $C:true is a checked box.
All my code runs beautifully when the array does contain the whole word as the text box is created and has the proper prefilled value. This however isn't always the case and it some listing agreements we see text boxes next to each other sometimes one works and the other doesn't. Sometimes the array element contains a sentence instead of works. I was expecting that every array value should be one word.
I'm not set on using ":" as a separator. If this will always combine words using a different separator let me know. Like if I did something like $T*John and that was guaranteed to always work, I'm fine with that.
AA
Akshaya Arivoli
Syncfusion Team
September 11, 2019 12:59 PM UTC
Hi Joe,
Based on the provided details we suspect that your requirement is to add text box for the searched words with the prefilled text in that. So, we have modified the provided code snippet to add text box with prefilled text and shared the same in the following location,
Please try this and revert us with more details about your requirement id you still have any concerns. Else we can setup a web meeting to look into it and provide the solution. Please let us know your availability. We will make every effort to have this scheduled on a date and time of your convenience.
Regards,
Akshaya
Hi Joe,
Based on the provided details we suspect that your requirement is to add text box for the searched words with the prefilled text in that. So, we have modified the provided code snippet to add text box with prefilled text and shared the same in the following location,
Please try this and revert us with more details about your requirement id you still have any concerns. Else we can setup a web meeting to look into it and provide the solution. Please let us know your availability. We will make every effort to have this scheduled on a date and time of your convenience.
Regards,Akshaya
The version you just gave doesn't work for us as the prefilled items are $T$ instead of the English words that are supposed to fill them.
I see you commented out my line: editableField.Text = word.Text?.Split(':')?.LastOrDefault()?.Replace("__", " ")?.Trim() ?? String.Empty;
This is the line that does exactly what I want. I split the word on ":" and anything after the : is what I want to fill in the text box with. So the string "$T$:John__Smith" should get me a text box that is filled in with "John Smith". Since I expect that each word in the text extraction should be together, I make any spaces __ so the end results is one word which you can see from this being one connected string "$T$:John__Smith", My code removes the __ and replaces it with spaces so when its put back in the textbox it shows as English words.
So to make the sample good the following lines:
This part should be text first eligible. $T$:
This part should be text first eligible. $T$:John__Smith
This part should be text Last eligible. $T$:Smith
Should be like this where I make [ ] being the editable textbox
This part should be text first eligible. [ ]
This part should be text first eligible. [ John Smith ]
This part should be text Last eligible. [ Smith ]
My code above would work perfectly if the text extraction array of all the words in the document was actually all the words in the document instead of breaking apart some words.
AA
Akshaya Arivoli
Syncfusion Team
September 12, 2019 12:57 PM UTC
Hi Joe,
Based on the provided details we suspect that your requirement is to add the text box for the text(John__Smith) next to the searched text ($T$:), also wants to replace the ‘_’ with space.
But in the provided code snippet, you have searched this text ($T$:) only and then Split that with the Colon(‘:’) then added the text box for that. There is no code related to add the textbox for (John_Shmith).
If you have searched for the text($T$:) then it will return the text available in that array only, not the whole word ($T$:John__Smith) . If you are aware of the text which you want to add text box then you can search for that word itself.
Note: The text will be extracted based on the format which is preserved in PDF document structure and not necessarily word without space ( $T$:John__Smith) should be preserved as single word. For the provided document “$T$:” and “John__Smith” will be rendered separately( as per document structure) so it will not be in same array.
Please revert us with more details about your requirement if you still have any concerns on this.
Regards,
Akshaya
Hi Joe,Based on the provided details we suspect that your requirement is to add the text box for the text(John__Smith) next to the searched text ($T$:), also wants to replace the ‘_’ with space.But in the provided code snippet, you have searched this text ($T$:) only and then Split that with the Colon(‘:’) then added the text box for that. There is no code related to add the textbox for (John_Shmith).If you have searched for the text($T$:) then it will return the text available in that array only, not the whole word ($T$:John__Smith) . If you are aware of the text which you want to add text box then you can search for that word itself.Note: The text will be extracted based on the format which is preserved in PDF document structure and not necessarily word without space ( $T$:John__Smith) should be preserved as single word. For the provided document “$T$:” and “John__Smith” will be rendered separately( as per document structure) so it will not be in same array.Please revert us with more details about your requirement if you still have any concerns on this.
Regards,Akshaya
When you say: "For the provided document “$T$:” and “John__Smith” will be rendered separately( as per document structure) so it will not be in same array." how do I get it to render together? For example in crystal reports it is just one text block, no reason it should be separate.
Your statements on "But in the provided code snippet, you have searched this text ($T$:) only and then Split that with the Colon(‘:’) then added the text box for that. There is no code related to add the textbox for (John_Shmith).
If you have searched for the text($T$:) then it will return the text available in that array only, not the whole word ($T$:John__Smith) . If you are aware of the text which you want to add text box then you can search for that word itself. "
Is incorrect. You can see from the following code:
//Define the key that will show where to put a text box.
String key = "$T$:";
//Search for the text given in the key.
List<TextData> found_texts = page_text.Value.Where(w => w.Text.Contains(key)).ToList();
That it will bring back any array items that CONTAIN the string "$T$:" therefore if the array contained an entry "$T$:John__Smith", it would bring back the whole word.
I then set the textboxfield value using:
//Define the prefilled text.
editableField.Text = word.Text?.Split(':')?.LastOrDefault()?.Replace("__", " ")?.Trim() ?? String.Empty;
Which will give me anything past the : and replace anything in that string where the __ is with a blank space. Therefore after this code is run editableField.Text = "John Smith" and since I'm setting the text, the value is prefilled in the text box.
In doing this, I have found the element via contains without needing to know the value before hand and then prefilled the textbox text with that value.
The point is my code does everything it needs to for this to work, the issue is that the ExtractText call isn't getting me words, but random words and phrases in the document. Other documents work 100% fine while some work 50% fine and some like the example I gave, don't work at all. I need it to be 100% all the time to use it unless you can think of another way to have textboxes created dynamically and prefilled with a value given in the PDF that isn't know before.
AA
Akshaya Arivoli
Syncfusion Team
September 13, 2019 11:47 AM UTC
Hi Joe,
Please find the details from the below,
|
Query |
Details |
|
When you say: "For the provided document “$T$:” and “John__Smith” will be rendered separately( as per document structure) so it will not be in same array." how do I get it to render together? For example in crystal reports it is just one text block, no reason it should be separate. |
The format of the text content in the PDF document depends on the pdf creator which is creating the PDF document, not based on the crystal report format.
The text will be rendered and extracted from the PDF document based on the TJ operators. The text available in single TJ operator is decided by the pdf creator, while creating the document stream, so it may contain single character or single word or multiple words. |
|
If you have searched for the text($T$:) then it will return the text available in that array only, not the whole word ($T$:John__Smith) . If you are aware of the text which you want to add text box then you can search for that word itself. "
Is incorrect. You can see from the following code:
//Define the key that will show where to put a text box.
String key = "$T$:";
//Search for the text given in the key.
List<TextData> found_texts = page_text.Value.Where(w => w.Text.Contains(key)).ToList();
That it will bring back any array items that CONTAIN the string "$T$:" therefore if the array contained an entry "$T$:John__Smith", it would bring back the whole word.
I then set the textboxfield value using:
//Define the prefilled text.
editableField.Text = word.Text?.Split(':')?.LastOrDefault()?.Replace("__", " ")?.Trim() ?? String.Empty;
Which will give me anything past the : and replace anything in that string where the __ is with a blank space. Therefore after this code is run editableField.Text = "John Smith" and since I'm setting the text, the value is prefilled in the text box.
In doing this, I have found the element via contains without needing to know the value before hand and then prefilled the textbox text with that value.
|
Yes, if you search for the string “$TS:” it will return the array items that contains the provide string.
But for the provided document array item contains only “$TS:”. The text will be rendered and extracted from the PDF document based on the TJ operators. An array item in the TextData will contain the text available in single TJ operator.
Please find the below screenshot showing that the text ($T$:) and (John__Smith) are preserved in two different TJ operators. So those texts are in differed array in the extracted text.
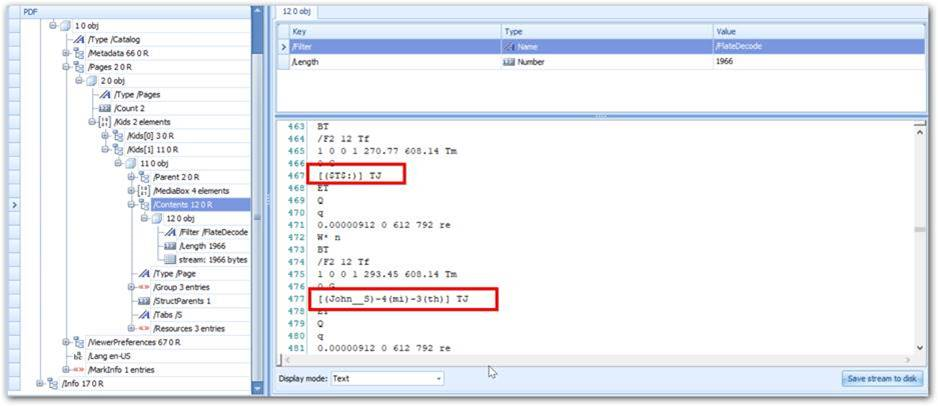 |
Please let us know if you have any concerns on this.
Regards,
Akshaya
JO
Joe
September 13, 2019 04:02 PM UTC
Is there a way to manipulate TJ operators to always include the full word? Like maybe I shouldn't use ":" as the separator but maybe a different character?
Crystal reports just uses a text block and I type the text in with no spaces. I don't control TJ operators and wouldn't see why it's seperating.
The document I made for you, I used Microsoft Word and typed it in normally and then saved it as a PDF and as you can see, the TJ operators you mentioned are wrong for that one.
AA
Akshaya Arivoli
Syncfusion Team
September 16, 2019 10:56 AM UTC
Hi Joe,
As mentioned earlier, the format of the text content in the PDF document depends on the pdf creator which is creating the PDF document, not based on the crystal report format. So it is not necessarily a string with no spaces should be with single TJ operator while creating, it may be divided into number of TJ operators(depends on the pdf creator). Also we are extracting the text from the PDF document based on TJ operators.
Please let us know if you have any concerns on this.
Regards,
Akshaya
JO
Joe
September 17, 2019 10:46 PM UTC
Do you have any other suggestions on how we can make a PDF editable after it's creation?
AA
Akshaya Arivoli
Syncfusion Team
September 22, 2019 04:38 AM UTC
Hi Joe,
EJ2 PDF Viewer server library allows you to extract the text from a page along with the bounds. ExtractText() will return bounds of each character, using that we can get the bounds of the words. Then we can add the textbox field for the words using the PdfLoadedDocument as per your requirement. We have created the sample for the same and shared in the following location,
Please find the below UG link to extract the text from the PDF document,
Please find the below KB to get the bounds of the words from the extracted text ,
Please try this and let us know if you have any concerns on this.
Regards,
Akshaya
Hi Joe,EJ2 PDF Viewer server library allows you to extract the text from a page along with the bounds. ExtractText() will return bounds of each character, using that we can get the bounds of the words. Then we can add the textbox field for the words using the PdfLoadedDocument as per your requirement. We have created the sample for the same and shared in the following location,
Please find the below UG link to extract the text from the PDF document,
Please find the below KB to get the bounds of the words from the extracted text ,
Please try this and let us know if you have any concerns on this.
Regards,Akshaya
Hey,
I've tried this and it seems to have worked locally with the file I gave you. I moved it to our staging server which mirrors production and got the following error when running the code:
"Access to the path *path* is denied."
I'm not sure where that path came from or why it needs access to it. Is this a cache directory? If so can I point that to another temp folder that does have permission?
I had to censor the path and error as it wouldn't let me post since it said I tried to enter a word or url that was not allowed.
I am using the [email protected]
SA
Sabari Anand Senthamarai Kannan
Syncfusion Team
October 2, 2019 02:31 PM UTC
Hi Joe,
Thank you for the update.
We do not use cache directory or access TEMP folder in Syncfusion.EJ2.PdfViewer library. We suspect that the path of the PDF document is not accessed properly in the web server application when hosted. Please use the below code snippet to access the document in your application.
Code Snippet:
|
HttpContext.Current.Server.MapPath("~/Data/Test Form.pdf”);
|
The above code will get the PDF document from the Data folder in the project folder’s location. Please try the above solution in your application and revert us if any issues faced. If you are facing issues, please provide us the following details. So that we can try to reproduce the issue in that environment.
- Operating System:
- RAM:
- System Culture:
- .NET Framework version:
- Hosted application is ASP.NET MVC, ASP.NET Core or ASP.NET webforms?
Please let us know if you need any further assistance.
Regards,
Sabari Anand
JO
Joe
October 2, 2019 03:19 PM UTC
We do not load the PDF from a file location but rather from a byte array passed in. The PDF is generated using crystal reports on the fly so it never actually physically exists on the server. We use the following code to start the renderer:
//Create the JS server PDF renderer.
PdfRenderer renderer = new PdfRenderer();
//Load the PDF document in PDF Viewer server library.
renderer.Load(report_bytes);
For your questions on the system.
- Operating System:
- RAM:
- System Culture:
- .NET Framework version:
- Hosted application is ASP.NET MVC, ASP.NET Core or ASP.NET webforms?
I'm also going to try and post the error again but I'll have to change some stuff as it's not letting me post cause of a word.
The type initializer for *Pdfium Native* threw an exception.
Access to the path 'C:\Windows\SysWOW64\inetsrv\x86\' is denied.
AA
Akshaya Arivoli
Syncfusion Team
October 3, 2019 10:35 AM UTC
Hi Joe,
Based on the provided details we suspect that, the project residing folder does not have write access. We have embedded Pdfium rendering engine in our PDF Viewer for robust rendering, so Pdfium dll will be generated while running the project. So kindly place your project, which has access to read and write files. Else, please copy the Pdfium assemblies manually inside the Pdfium folder(‘’C:\Windows\SysWOW64\inetsrv\x86\’’) for resolving the reported issue. Also, you can build the project in local folder(which have read and write access) and then copy the files for hosting in the remote machine. The Pdfium assembly will be available in this case.
Note: Once we manually copied the Pdfium assemblies then the PDF Viewer will not generate the assembly again.
Regards,
Akshaya
Hi Joe,Based on the provided details we suspect that, the project residing folder does not have write access. We have embedded Pdfium rendering engine in our PDF Viewer for robust rendering, so Pdfium dll will be generated while running the project. So kindly place your project, which has access to read and write files. Else, please copy the Pdfium assemblies manually inside the Pdfium folder(‘’C:\Windows\SysWOW64\inetsrv\x86\’’) for resolving the reported issue. Also, you can build the project in local folder(which have read and write access) and then copy the files for hosting in the remote machine. The Pdfium assembly will be available in this case.Note: Once we manually copied the Pdfium assemblies then the PDF Viewer will not generate the assembly again.Regards,Akshaya
Where can I find the Pdfium dlls to copy to that folder? Is that on nuget? If so what is the name?
MS
Mohan Selvaraj
Syncfusion Team
October 4, 2019 11:26 AM UTC
Hi joe,
The pdfium dll is added in the Syncfusion.EJ2.PdfViewer dll as embedded resource. We extract and place it in the application folder during the run time. However, we have shared the pdfium assembly for Windows(X64 and X86),Linux and Mac operating system .Kindly download the same from the below link.
Example (windows reference):
Package location: ~\packages\syncfusion.ej2.pdfviewer.aspnet.core.windows\17.3.0.10\lib\netstandard2.0
Please let us know if you have any concerns about on it.
Regards,
Mohan S
JO
Joe
October 4, 2019 03:26 PM UTC
I placed those dlls where it was asked and it worked and the PDF prints now. We will put it through testing now to see if it fits but so far initial testing is good. We are getting consistent textboxes being created with the values being populated.
SA
Sabari Anand Senthamarai Kannan
Syncfusion Team
October 7, 2019 12:03 PM UTC
Hi Joe,
Thank you for the update.
We are happy to hear that the provided solution resolved your issue. Please let us know if you need any further assistance in this after the testing.
Regards,
Sabari Anand
SIGN IN To post a reply.
- 22 Replies
- 6 Participants
-
JO Joe
- Sep 3, 2019 08:29 PM UTC
- Oct 7, 2019 12:03 PM UTC
