
Support Vector Machines Succinctly®

CHAPTER 8
The SMO Algorithm
We saw how to solve the SVM optimization problem using a convex optimization package. However, in practice, we will use an algorithm specifically created to solve this problem quickly: the SMO (sequential minimal optimization) algorithm. Most machine learning libraries use the SMO algorithm or some variation.
The SMO algorithm will solve the following optimization problem:
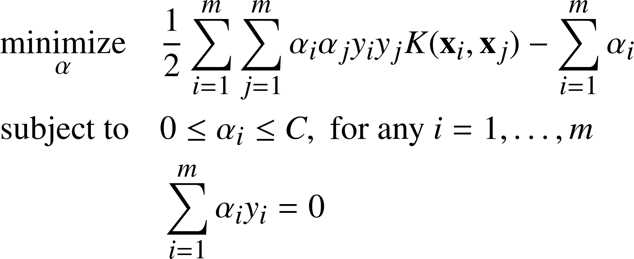
It is a kernelized version of the soft-margin formulation we saw in Chapter 5. The objective function we are trying to minimize can be written in Python (Code Listing 37):
def kernel(x1, x2): def objective_function_to_minimize(X, y, a, kernel): |
This is the same problem we solved using CVXOPT. Why do we need another method? Because we would like to be able to use SVMs with big datasets, and using convex optimization packages usually involves matrix operations that take a lot of time as the size of the matrix increases or become impossible because of memory limitations. The SMO algorithm has been created with the goal of being faster than other methods.
The idea behind SMO
When we try to solve the SVM optimization problem, we are free to change the values of ![]() as long as we respect the constraints. Our goal is to modify
as long as we respect the constraints. Our goal is to modify ![]() so that in the end, the objective function returns the smallest possible value. In this context, given a vector
so that in the end, the objective function returns the smallest possible value. In this context, given a vector ![]() of Lagrange multipliers, we can change the value of any
of Lagrange multipliers, we can change the value of any ![]() until we reach our goal.
until we reach our goal.
The idea behind SMO is quite easy: we will solve a simpler problem. That is, given a vector ![]() , we will allow ourselves to change only two values of
, we will allow ourselves to change only two values of ![]() , for instance,
, for instance, ![]() and
and ![]() . We will change them until the objective function reaches its minimum given this set of alphas. Then we will pick two other alphas and change them until the function returns its smallest value, and so on. If we continue doing that, we will eventually reach the minimum of the objective function of the original problem.
. We will change them until the objective function reaches its minimum given this set of alphas. Then we will pick two other alphas and change them until the function returns its smallest value, and so on. If we continue doing that, we will eventually reach the minimum of the objective function of the original problem.
SMO solves a sequence of several simpler optimization problems.
How did we get to SMO?
This idea of solving several simpler optimization problems is not new. In 1982, Vapnik proposed a method known as “chunking,” which breaks the original problem down into a series of smaller problems (Vapnik V. , 1982). What made things change is that in 1997, Osuna, et al., proved that solving a sequence of sub-problems will be guaranteed to converge as long as we add at least one example violating the KKT conditions (Osuna, Freund, & Girosi, 1997).
Using this result, one year later, in 1998, Platt proposed the SMO algorithm.
Why is SMO faster?
The great advantage of the SMO approach is that we do not need a QP solver to solve the problem for two Lagrange multipliers—it can be solved analytically. As a consequence, it does not need to store a huge matrix, which can cause problems with machine memory. Moreover, SMO uses several heuristics to speed up the computation.
The SMO algorithm
The SMO algorithm is composed of three parts:
- One heuristic to choose the first Lagrange multiplier
- One heuristic to choose the second Lagrange multiplier
- The code to solve the optimization problem analytically for the two chosen multipliers
Tip: A Python implementation of the algorithm is available in Appendix B: The SMO Algorithm. All code listings in this section are taken from this appendix and do not work alone.
The analytical solution
At the beginning of the algorithm, we start with a vector ![]() in which
in which ![]() . The idea is to pick two elements of this vector, which we will name
. The idea is to pick two elements of this vector, which we will name ![]() and
and ![]() , and to change their values so that the constraints are still respected.
, and to change their values so that the constraints are still respected.
The first constraint ![]() means that
means that ![]() and
and ![]() . That is why we are forced to select a value lying in the blue box of Figure 50 (which displays an example where
. That is why we are forced to select a value lying in the blue box of Figure 50 (which displays an example where ![]() ).
).
The second constraint is a linear constraint ![]() . It forces the values to lie on the red diagonal, and the first couple of selected
. It forces the values to lie on the red diagonal, and the first couple of selected ![]() and
and ![]() should have different labels (
should have different labels (![]() ).
).

Figure 50: The feasible set is the diagonal of the box
In general, to avoid breaking the linear constraint, we must change the multipliers so that:
![]()
We will not go into the details of how the problem is solved analytically, as it is done very well in (Cristianini & Shawe-Taylor, 2000) and in (Platt J. C., 1998).
Remember that there is a formula to compute the new ![]() :
:
![]()
with ![]() being the difference between the output of the hypothesis function and the example label.
being the difference between the output of the hypothesis function and the example label. ![]() is the kernel function. We also compute bounds, which applies to
is the kernel function. We also compute bounds, which applies to ![]() ; it cannot be smaller than the lower bound, or larger than the upper bound, or constraints will be violated. So
; it cannot be smaller than the lower bound, or larger than the upper bound, or constraints will be violated. So ![]() is clipped if this is the case.
is clipped if this is the case.
Once we have this new value, we use it to compute the new ![]() using this formula:
using this formula:
![]()
Understanding the first heuristic
The idea behind the first heuristic is pretty simple: each time SMO examines an example, it checks whether or not the KKT conditions are violated. Recall that at least one KKT condition must be violated. If the conditions are met, then it tries another example. So if there are millions of examples, and only a few of them violate the KKT conditions, it will spend a lot of time examining useless examples. In order to avoid that, the algorithm concentrates its time on examples in which the Lagrange multiplier is not equal to 0 or ![]() , because they are the most likely to violate the conditions (Code Listing 38).
, because they are the most likely to violate the conditions (Code Listing 38).
def get_non_bound_indexes(self): |
Because solving the problem analytically involves two Lagrange multipliers, it is possible that a bound multiplier (whose value is between 0 and ![]() ) has become KKT-violated. That is why the main routine alternates between all examples and the non-bound subset (Code Listing 39). Note that the algorithm finishes when progress is no longer made.
) has become KKT-violated. That is why the main routine alternates between all examples and the non-bound subset (Code Listing 39). Note that the algorithm finishes when progress is no longer made.
def main_routine(self): |
Understanding the second heuristic
The goal of this second heuristic is to select the Lagrange multiplier for which the step taken will be maximal.
How do we update ![]() ? We use the following formula:
? We use the following formula:
![]()
Remember that in this case that we have already chosen the value ![]() . Our goal is to pick the
. Our goal is to pick the ![]() whose
whose ![]() will have the biggest change. This formula can be rewritten as follows:
will have the biggest change. This formula can be rewritten as follows:
![]()
with:
![]()
So, to pick the best ![]() amongst several
amongst several ![]() , we need to compute the value of step for each
, we need to compute the value of step for each ![]() and select the one with the biggest step. The problem here is that we need to call the kernel function
and select the one with the biggest step. The problem here is that we need to call the kernel function ![]() three times for each step, and this is costly. Instead of doing that, Platt came with the following approximation:
three times for each step, and this is costly. Instead of doing that, Platt came with the following approximation:
![]()
As a result, selecting the biggest step is done by taking the ![]() with the smallest error if
with the smallest error if ![]() is positive, and the
is positive, and the ![]() with the biggest error if
with the biggest error if ![]() is negative.
is negative.
This approximation is visible in the method second_heuristic of Code Listing 40.
def second_heuristic(self, non_bound_indices): if step > max: def examine_example(self, i2): if i1 >= 0 and self.take_step(i1, i2): # progress by looping over all non-zero and non-C alpha, # starting at a random point. # by looping over all possible examples, starting at a random # point. |
Summary
Understanding the SMO algorithm can be tricky because a lot of the code is here for performance reasons, or to handle specific degenerate cases. However, at its core, the algorithm remains simple and is faster than convex optimization solvers. Over time, people have discovered new heuristics to improve this algorithm, and popular libraries like LIBSVM use an SMO-like algorithm. Note that even if this is the standard way of solving the SVM problem, other methods exist, such as gradient descent and stochastic gradient descent (SGD), which is particularly used for online learning and dealing with huge datasets.
Knowing how the SMO algorithm works will help you decide if it is the best method for the problem you want to solve. I strongly advise you to try implementing it yourself. In the Stanford CS229 course, you can find the description of a simplified version of the algorithm, which is a good start. Then, in Sequential Minimal Optimization (Platt J. C., 1998), you can read the full description of the algorithm. The Python code available in Appendix B has been written from the pseudo-code from this paper and indicates in comments which parts of the code correspond to which equations in the paper.
- 1800+ high-performance UI components.
- Includes popular controls such as Grid, Chart, Scheduler, and more.
- 24x5 unlimited support by developers.