
Support Vector Machines Succinctly®

CHAPTER 5
Solving the Optimization Problem
Lagrange multipliers
The Italian-French mathematician Giuseppe Lodovico Lagrangia, also known as Joseph-Louis Lagrange, invented a strategy for finding the local maxima and minima of a function subject to equality constraint. It is called the method of Lagrange multipliers.
The method of Lagrange multipliers
Lagrange noticed that when we try to solve an optimization problem of the form:
![]()
the minimum of ![]() is found when its gradient point in the same direction as the gradient of
is found when its gradient point in the same direction as the gradient of ![]() .
.
In other words, when:
![]()
So if we want to find the minimum of ![]() under the constraint
under the constraint ![]() , we just need to solve for:
, we just need to solve for:
![]()
Here, the constant ![]() is called a Lagrange multiplier.
is called a Lagrange multiplier.
To simplify the method, we observe that if we define a function ![]() , then its gradient is
, then its gradient is ![]() . As a result, solving for
. As a result, solving for ![]() allows us to find the minimum.
allows us to find the minimum.
The Lagrange multiplier method can be summarized by these three steps:
- Construct the Lagrangian function
![%FontSize=11
%TeXFontSize=11
\documentclass{article}
\pagestyle{empty}
\begin{document}
\[
\mathcal{L}
\]
\end{document}](https://s3.amazonaws.com/ebooks.syncfusion.com/LiveReadOnlineFiles/support_vector_machines_succinctly/Images/Images\483.png) by introducing one multiplier per constraint
by introducing one multiplier per constraint - Get the gradient
![%FontSize=11
%TeXFontSize=11
\documentclass{article}
\pagestyle{empty}
\begin{document}
\[
\nabla\mathcal{L}
\]
\end{document}](https://s3.amazonaws.com/ebooks.syncfusion.com/LiveReadOnlineFiles/support_vector_machines_succinctly/Images/Images\484.png) of the Lagrangian
of the Lagrangian - Solve for
![%FontSize=11
%TeXFontSize=11
\documentclass{article}
\pagestyle{empty}
\begin{document}
\[
\nabla\mathcal{L}(\mathbf{x}, \alpha)=0
\]
\end{document}](https://s3.amazonaws.com/ebooks.syncfusion.com/LiveReadOnlineFiles/support_vector_machines_succinctly/Images/Images\485.png)
The SVM Lagrangian problem
We saw in the last chapter that the SVM optimization problem is:

Let us return to this problem. We have one objective function to minimize:
![]()
and ![]() constraint functions:
constraint functions:
![]()
We introduce the Lagrangian function:
![]()
![]()
Note that we introduced one Lagrange multiplier ![]() for each constraint function.
for each constraint function.
We could try to solve for ![]() , but the problem can only be solved analytically when the number of examples is small (Tyson Smith, 2004). So we will once again rewrite the problem using the duality principle.
, but the problem can only be solved analytically when the number of examples is small (Tyson Smith, 2004). So we will once again rewrite the problem using the duality principle.
To get the solution of the primal problem, we need to solve the following Lagrangian problem:
![]()
What is interesting here is that we need to minimize with respect to ![]() and
and ![]() , and to maximize with respect to
, and to maximize with respect to ![]() at the same time.
at the same time.
Tip: You may have noticed that the method of Lagrange multipliers is used for solving problems with equality constraints, and here we are using them with inequality constraints. This is because the method still works for inequality constraints, provided some additional conditions (the KKT conditions) are met. We will talk about these conditions later.
The Wolfe dual problem
The Lagrangian problem has ![]() inequality constraints (where
inequality constraints (where ![]() is the number of training examples) and is typically solved using its dual form. The duality principle tells us that an optimization problem can be viewed from two perspectives. The first one is the primal problem, a minimization problem in our case, and the other one is the dual problem, which will be a maximization problem. What is interesting is that the maximum of the dual problem will always be less than or equal to the minimum of the primal problem (we say it provides a lower bound to the solution of the primal problem).
is the number of training examples) and is typically solved using its dual form. The duality principle tells us that an optimization problem can be viewed from two perspectives. The first one is the primal problem, a minimization problem in our case, and the other one is the dual problem, which will be a maximization problem. What is interesting is that the maximum of the dual problem will always be less than or equal to the minimum of the primal problem (we say it provides a lower bound to the solution of the primal problem).
In our case, we are trying to solve a convex optimization problem, and Slater’s condition holds for affine constraints (Gretton, 2016), so Slater’s theorem tells us that strong duality holds. This means that the maximum of the dual problem is equal to the minimum of the primal problem. Solving the dual is the same thing as solving the primal, except it is easier.
Recall that the Lagrangian function is:
![%FontSize=11
%TeXFontSize=11
\documentclass{article}
\pagestyle{empty}
\begin{document}
\begin{equation*}
\begin{split}
\mathcal{L}(\mathbf{w},b,\alpha) & = \frac{1}{2}\|\mathbf{w}\|^2- \sum\limits_{i=1}^m \alpha_i\big[y_i(\mathbf{w}\cdot\mathbf{x}_i+b)-1\big]
\\ & = \frac{1}{2}\mathbf{w}\cdot\mathbf{w}- \sum\limits_{i=1}^m \alpha_i\big[y_i(\mathbf{w}\cdot\mathbf{x}_i+b)-1\big]
\end{split}
\end{equation*}
\end{document}](https://s3.amazonaws.com/ebooks.syncfusion.com/LiveReadOnlineFiles/support_vector_machines_succinctly/Images/Images\500.png)
The Lagrangian primal problem is:
![]()
Solving the minimization problem involves taking the partial derivatives of ![]() with respect to
with respect to ![]() and
and ![]() .
.
![]()
![]()
From the first equation, we find that:
![]()
Let us substitute ![]() by this value into
by this value into ![]() :
:
![%FontSize=11
%TeXFontSize=11
\documentclass{article}
\pagestyle{empty}
\begin{document}
\begin{equation*}
\begin{split}
W(\alpha,b) & = \frac{1}{2}\bigg(\sum\limits_{i=1}^m \alpha_i y_i \mathbf{x}_i\bigg)\cdot\bigg(\sum\limits_{j=1}^m \alpha_j y_j \mathbf{x}_j\bigg)- \sum\limits_{i=1}^m \alpha_i\bigg[y_i\bigg((\sum\limits_{j=1}^m \alpha_j y_j \mathbf{x}_j)\cdot\mathbf{x}_i+b\bigg)-1\bigg]
\\ & = \frac{1}{2}\sum\limits_{i=1}^m \sum\limits_{j=1}^m \alpha_i\alpha_j y_i y_j \mathbf{x}_i\cdot \mathbf{x}_j- \sum\limits_{i=1}^m \alpha_i y_i\bigg((\sum\limits_{j=1}^m \alpha_j y_j \mathbf{x}_j)\cdot\mathbf{x}_i+b\bigg)+\sum\limits_{i=1}^m \alpha_i
\\ & = \frac{1}{2}\sum\limits_{i=1}^m \sum\limits_{j=1}^m \alpha_i\alpha_j y_i y_j \mathbf{x}_i\cdot \mathbf{x}_j- \sum\limits_{i=1}^m \sum\limits_{j=1}^m \alpha_i \alpha_j y_i y_j \mathbf{x}_i\cdot\mathbf{x}_j -b\sum\limits_{i=1}^m \alpha_i y_i +\sum\limits_{i=1}^m \alpha_i
\\ & = \sum\limits_{i=1}^m \alpha_i -\frac{1}{2}\sum\limits_{i=1}^m \sum\limits_{j=1}^m \alpha_i\alpha_j y_i y_j \mathbf{x}_i\cdot \mathbf{x}_j -b\sum\limits_{i=1}^m \alpha_i y_i
\end{split}
\end{equation*}
\end{document}](https://s3.amazonaws.com/ebooks.syncfusion.com/LiveReadOnlineFiles/support_vector_machines_succinctly/Images/Images\510.png)
So we successfully removed ![]() , but
, but ![]() is still used in the last term of the function:
is still used in the last term of the function:
![]()
We note that ![]() implies that
implies that ![]() . As a result, the last term is equal to zero, and we can write:
. As a result, the last term is equal to zero, and we can write:
![]()
This is the Wolfe dual Lagrangian function.
The optimization problem is now called the Wolfe dual problem:

Traditionally the Wolfe dual Lagrangian problem is constrained by the gradients being equal to zero. In theory, we should add the constraints ![]() and
and ![]() . However, we only added the latter. Indeed, we added
. However, we only added the latter. Indeed, we added ![]() because it is necessary for removing
because it is necessary for removing ![]() from the function. However, we can solve the problem without the constraint
from the function. However, we can solve the problem without the constraint ![]() .
.
The main advantage of the Wolfe dual problem over the Lagrangian problem is that the objective function ![]() now depends only on the Lagrange multipliers. Moreover, this formulation will help us solve the problem in Python in the next section and will be very helpful when we define kernels later.
now depends only on the Lagrange multipliers. Moreover, this formulation will help us solve the problem in Python in the next section and will be very helpful when we define kernels later.
Karush-Kuhn-Tucker conditions
Because we are dealing with inequality constraints, there is an additional requirement: the solution must also satisfy the Karush-Kuhn-Tucker (KKT) conditions.
The KKT conditions are first-order necessary conditions for a solution of an optimization problem to be optimal. Moreover, the problem should satisfy some regularity conditions. Luckily for us, one of the regularity conditions is Slater’s condition, and we just saw that it holds for SVMs. Because the primal problem we are trying to solve is a convex problem, the KKT conditions are also sufficient for the point to be primal and dual optimal, and there is zero duality gap.
To sum up, if a solution satisfies the KKT conditions, we are guaranteed that it is the optimal solution.
The Karush-Kuhn-Tucker conditions are:
- Stationarity condition:
![]()
![]()
- Primal feasibility condition:
![]()
- Dual feasibility condition:
![]()
- Complementary slackness condition:
![]()
Note: “[...]Solving the SVM problem is equivalent to finding a solution to the KKT conditions.” (Burges, 1988)
Note that we already saw most of these conditions before. Let us examine them one by one.
Stationarity condition
The stationarity condition tells us that the selected point must be a stationary point. It is a point where the function stops increasing or decreasing. When there is no constraint, the stationarity condition is just the point where the gradient of the objective function is zero. When we have constraints, we use the gradient of the Lagrangian.
Primal feasibility condition
Looking at this condition, you should recognize the constraints of the primal problem. It makes sense that they must be enforced to find the minimum of the function under constraints.
Dual feasibility condition
Similarly, this condition represents the constraints that must be respected for the dual problem.
Complementary slackness condition
From the complementary slackness condition, we see that either ![]() or
or ![]() .
.
Support vectors are examples having a positive Lagrange multiplier. They are the ones for which the constraint ![]() is active. (We say the constraint is active when
is active. (We say the constraint is active when ![]() ).
).
Tip: From the complementary slackness condition, we see that support vectors are examples that have a positive Lagrange multiplier.
What to do once we have the multipliers?
When we solve the Wolfe dual problem, we get a vector ![]() containing all Lagrange multipliers. However, when we first stated the primal problem, our goal was to find
containing all Lagrange multipliers. However, when we first stated the primal problem, our goal was to find ![]() and
and ![]() . Let us see how we can retrieve these values from the Lagrange multipliers.
. Let us see how we can retrieve these values from the Lagrange multipliers.
Compute w
Computing ![]() is pretty simple since we derived the formula:
is pretty simple since we derived the formula: ![]() from the gradient
from the gradient ![]() .
.
Compute b
Once we have ![]() , we can use one of the constraints of the primal problem to compute
, we can use one of the constraints of the primal problem to compute ![]() :
:
![]()
Indeed, this constraint is still true because we transformed the original problem in such a way that the new formulations are equivalent. What it says is that the closest points to the hyperplane will have a functional margin of 1 (the value 1 is the value we chose when we decided how to scale ![]() ):
):
![]()
From there, as we know all other variables, it is easy to come up with the value of ![]() . We multiply both sides of the equation by
. We multiply both sides of the equation by ![]() , and because
, and because ![]() , it gives us:
, it gives us:
![]()
![]()
However, as indicated in Pattern Recognition and Machine Learning (Bishop, 2006), instead of taking a random support vector ![]() , taking the average provides us with a numerically more stable solution:
, taking the average provides us with a numerically more stable solution:
![]()
where ![]() is the number of support vectors.
is the number of support vectors.
Other authors, such as (Cristianini & Shawe-Taylor, 2000) and (Ng), use another formula:
![]()
They basically take the average of the nearest positive support vector and the nearest negative support vector. This latest formula is the one originally used by Statistical Learning Theory (Vapnik V. N., 1998) when defining the optimal hyperplane.
Hypothesis function
The SVMs use the same hypothesis function as the Perceptron. The class of an example ![]() is given by:
is given by:
![]()
When using the dual formulation, it is computed using only the support vectors:
![]()
Solving SVMs with a QP solver
A QP solver is a program used to solve quadratic programming problems. In the following example, we will use the Python package called CVXOPT.
This package provides a method that is able to solve quadratic problems of the form:

It does not look like our optimization problem, so we will need to rewrite it so that we can solve it with this package.
First, we note that in the case of the Wolfe dual optimization problem, what we are trying to minimize is ![]() , so we can rewrite the quadratic problem with
, so we can rewrite the quadratic problem with ![]() instead of
instead of ![]() to better see how the two problems relate:
to better see how the two problems relate:

Here the ![]() symbol represents component-wise vector inequalities. It means that each row of the matrix
symbol represents component-wise vector inequalities. It means that each row of the matrix ![]() represents an inequality that must be satisfied.
represents an inequality that must be satisfied.
We will change the Wolfe dual problem. First, we transform the maximization problem:

into a minimization problem by multiplying by -1.

Then we introduce vectors ![]() and
and ![]() and the Gram matrix
and the Gram matrix ![]() of all possible dot products of vectors
of all possible dot products of vectors ![]() :
:

We use them to construct a vectorized version of the Wolfe dual problem where ![]() denotes the outer product of
denotes the outer product of ![]() .
.

We are now able to find out the value for each of the parameters ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() , and
, and ![]() required by the CVXOPT qp function. This is demonstrated in Code Listing 24.
required by the CVXOPT qp function. This is demonstrated in Code Listing 24.
# See Appendix A for more information about the dataset from succinctly.datasets import get_dataset, linearly_separable as ls import cvxopt.solvers X, y = get_dataset(ls.get_training_examples) # Gram matrix - The matrix of all possible inner products of X. |
Code Listing 24 initializes all the required parameters and passes them to the qp function, which returns us a solution. The solution contains many elements, but we are only concerned about the x, which, in our case, corresponds to the Lagrange multipliers.
As we saw before, we can re-compute ![]() using all the Lagrange multipliers:
using all the Lagrange multipliers: ![]() . Code Listing 25 shows the code of the function that computes
. Code Listing 25 shows the code of the function that computes ![]() .
.
def compute_w(multipliers, X, y): |
Because Lagrange multipliers for non-support vectors are almost zero, we can also compute ![]() using only support vectors data and their multipliers, as illustrated in Code Listing 26.
using only support vectors data and their multipliers, as illustrated in Code Listing 26.
w = compute_w(multipliers, X, y) print(w) # [0.44444446 1.11111114] |
And we compute b using the average method:
Code Listing 27
def compute_b(w, X, y): |
Code Listing 28
b = compute_b(w, support_vectors, support_vectors_y) # -9.666668268506335 |
When we plot the result in Figure 32, we see that the hyperplane is the optimal hyperplane. Contrary to the Perceptron, the SVM will always return the same result.
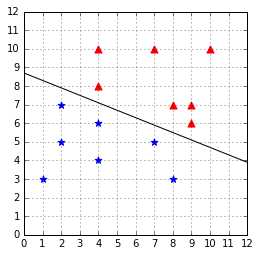
Figure 32: The hyperplane found with CVXOPT
This formulation of the SVM is called the hard margin SVM. It cannot work when the data is not linearly separable. There are several Support Vector Machines formulations. In the next chapter, we will consider another formulation called the soft margin SVM, which will be able to work when data is non-linearly separable because of outliers.
Summary
Minimizing the norm of ![]() is a convex optimization problem, which can be solved using the Lagrange multipliers method. When there are more than a few examples, we prefer using convex optimization packages, which will do all the hard work for us.
is a convex optimization problem, which can be solved using the Lagrange multipliers method. When there are more than a few examples, we prefer using convex optimization packages, which will do all the hard work for us.
We saw that the original optimization problem can be rewritten using a Lagrangian function. Then, thanks to duality theory, we transformed the Lagrangian problem into the Wolfe dual problem. We eventually used the package CVXOPT to solve the Wolfe dual.
- 1800+ high-performance UI components.
- Includes popular controls such as Grid, Chart, Scheduler, and more.
- 24x5 unlimited support by developers.