
Statistics Fundamentals Succinctly®

CHAPTER 7
ANOVA
Test for differences between three or more samples
When we have three or more samples and we want to determine if any two of them are significantly different from each other, we utilize a statistical test called analysis of variance (ANOVA). This test analyzes how a dependent variable differs based on one or more independent variables. For example, we may want to know if scores on a standardized math test (the dependent variable) are significantly different between students who go to School A, School B, and School C (where school is the independent variable).
The dependent variable should be continuous (math test scores are continuous), be approximately normally distributed, and have homogenous variances for the values for each of the groups. The independent variable should be categorical with mutually exclusive values (where “School A,” “School B,” and “School C” are the different values). The independent variable should also be approximately normally distributed.
This chapter covers both one-way and two-way ANOVA. In one-way ANOVA, there is one independent variable; in two-way ANOVA there are two independent variables.
Compare samples based on one factor
The null and alternative hypotheses are:
H0: μ1 = μ2 = … = μk
Ha: at least two population means are significantly different
where there are k samples.
This test involves measuring between-group variability—essentially, the variance of the sample means—and dividing between-group variability by a measure of within-group variability—a combined measure of each sample’s variance. The resulting quotient is the F-statistic.
F = (between-group variability) / (within-group variability)
The greater F is, the more likely at least two populations are significantly different. If you think about this quotient, greater between-group variability indicates that the sample means are spread out farther from each other, which implies they’re more likely to be significantly different.

Smaller between-group variability

Greater between-group variability
Figure 37: In the previous figure, within-group variability is the same, but between-group variability changes. As between-group variability increases, samples are more likely to be significantly different and the F-statistic increases.
On the other hand, greater within-group variability indicates that the standard deviation of each sample is greater, which implies the samples are less likely to be significantly different.

Smaller within-group variability

Greater within-group variability
Figure 38: In this figure, between-group variability is the same, but within-group variability changes. As within-group variability increases, samples are less likely to be significantly different and the F-statistic decreases.
So, the greater the numerator (between-group variability) and the smaller the denominator (within-group variability), the greater the F statistic will be. Let’s calculate each of these in turn.
Between-group variability
Measuring the spread of sample means is just like calculating the variance. First, we find the grand mean (![]() G), which is the sum of all values from each sample divided by the sum of each sample size.
G), which is the sum of all values from each sample divided by the sum of each sample size.
![]()
In the first expression, x1i represents all values from sample 1, x2i represents all values from sample 2, etc., while n1 is the size of sample 1, n2 is the size of sample 2, etc., for k samples; in the second expression, j is the sample number that ranges from 1 to k, while i is the value number in each respective sample.
To calculate between-group variability:
- Calculate the deviation of each sample mean from the grand mean:
 .
. - Square each deviation:
 .
. - Multiply each squared deviation by the sample size of that respective sample to weigh the squared deviation by the sample size:
 .
. - Sum each weighted squared deviation:
 .
.
This gives us the sum-of-squares for between-group variability (SSbetween). - Find the average squared deviation by dividing SSbetween by the degrees of freedom, where dfbetween = k – 1. This quotient is known as the mean square for between-group variability (MSbetween), and this is our final measure of between-group variability.
![]() .
.
Within-group variability
This is a measure of error that combines the error within each individual sample. To calculate within-group variability:
- Calculate the deviation of each value from the mean of the sample it comes from:
 .
. - Square each deviation:
 .
. - Sum the squared deviations:
 .
.
We now have the sum of squares for within-group variability (SSwithin). - Find the average squared deviation of each value from its respective sample mean by dividing SSwithin by dfwithin (the sum of the degrees of freedom of each sample), where dfwithin = (n1 - 1) + (n2 - 1) + … + (nk - 1) = n1 + n2 + … + nk - k = N – k. This quotient is the mean square for within-group variability (MSwithin) and is our final measure of within-group variability.
![]()
Total variability
If we take the deviation of each individual value from the grand mean, square each deviation, and find the sum of squared deviations, we get the total sum-of-squares (SStotal), a measure of the total variability. What’s cool is that SStotal is the sum of SSbetween and SSwithin.
SSbetween + SSwithin = SStotal
We often organize all our calculations in an ANOVA table.
Table 5: ANOVA tables help organize variability calculations.
SS | df | MS | F | |
Factor | SSbetween | dfbetween |
|
|
Error | SSwithin | dfwithin |
| |
Total | SSbetween + SSwithin | dfbetween + dfwithin |
The F-distribution
As with z- and t-statistics, F-statistics follow a specific distribution. In our calculation of between- and within-group variability, we (essentially) found average squared deviations. Therefore, F can never be negative, and the distribution lies along the positive x-axis.
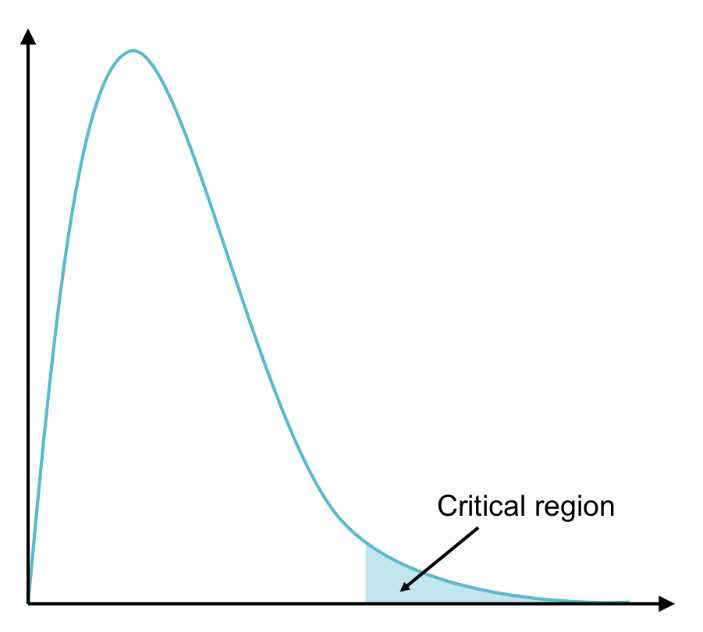
Figure 39: The F distribution has one tail on the right (on the positive x-axis). The critical region lies in this tail.
This also makes sense in the context of what we’re testing for—we simply want to know if at least two populations are significantly different, not if one is significantly less than or greater than another.
Once we’ve calculated the F-statistic, we use the F-table to determine the F-critical value,
F(α, dfbetween, dfwithin). You’ll see in the F-table that the column headers are dfbetween and the row headers are dfwithin. A specific F-table exists for each alpha level.
Example
As a digital marketer, you always try to determine the most effective means of advertising online. Let’s say you’ve placed ads with a number of online publications, in various locations on each web page, and you decide to perform ANOVA to determine if different locations have better click-through rates (CTR, which is the ratio between the percentage of users who click the ads and the total site visitors). The three most common ad locations are on the top, middle, and sides of the page. In your research, you find the CTR of more than 600 ads.
Table 6: This ANOVA table helps organize between-group and within-group variability calculations.
Top | Middle | Sides |
nT = 235
sT = 3.2% | nM = 169
sM = 4.3% | nS = 210
sS = 2.5% |
This gives us everything we need to calculate between-group and within-group variability.
Between-group variability:
![]()
We know that:

And therefore,
![]()
This leads us to SSbetween = (35 – 34.1)2 + (28 – 34.1)2 + (38 – 34.1)2 = 53.23
We also know the degrees of freedom for between-group variability (dfbetween) = 2 (because there are three categories for our independent variable (top, middle, sides) and we subtract 1.
Now we can find between-group variability.
![]()
Within-group variability:
By knowing each sample’s sum-of-squares, we can find SSwithin.

= 3.22(235 – 1) + 4.32(169 – 1) + 2.52(210 – 1) = 6808.73
We also know that the degrees of freedom for within-group variability (dfbetween) equals the total number of values minus the number of categories.
N – k = 235 + 169 + 210 – 3 = 611
Finally, we can find within-group variability (i.e. MSwithin) by dividing SSwithin by dfwithin.

F-statistic:
Finally, we can find the F-statistic.
![]()
We can organize all our calculations in an ANOVA table. You’ll get the same output when you do an ANOVA test in R, but the SS and df columns will be switched.
Table 7: Results of between-group and within-group variability calculations with F-statistic finding.
SS | df | MS | F | |
Page location | 53.23 | 2 | 26.62 | 2.39 |
Error | 6808.73 | 611 | 11.14 |
Once we’ve calculated the F statistic, we can compare this to the F-critical value
F(0.05, 2, 611) = 3.
Because the F-statistic is less than F(0.05, 2, 611), the results are not significant. Therefore, we fail to reject the null, and we conclude there is no evidence to suggest any two of the populations—where each population is the CTR for each ad location for all publications—are significantly different. In other words, there is no significant difference between the CTRs of different ad locations on web pages.
Now that we’ve performed one-way ANOVA by hand, let’s execute it in R with the NCES data. Let’s say we want to know if SES differs significantly by race (where subjects are coded 0 if they are “White”—see the Appendix for labels corresponding to other races). We’ll first apply the tapply() function, which tells us the statistic (e.g., mean, median) we will specify for a particular variable as broken out by the other variable. The tapply(ses, race, mean) function will take the mean of SES as broken out by race.
Next, we’ll use the term “fit” to name the ANOVA test, then we’ll summarize “fit” to see the results.
Code Listing 11
> tapply(ses, race, mean) #calculates the mean of income2011 based on the variable “race” 0 1 2 3 4 0.26154596 -0.29982456 0.06211096 -0.15877778 -0.39424116 5 6 -0.17442561 0.09525253 > fit = aov(ses ~ as.factor(race)) #label “fit” as the ANOVA test, ensure that the variable “race” is treated as a factor using as.factor() function > summary(fit) #summarize results of the ANOVA test Df Sum Sq Mean Sq F value Pr(>F) as.factor(race) 6 354 58.94 119 <2e-16 *** Residuals 8240 4080 0.50 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 |
You can see from the tapply() function that white students (code = 0) are of higher SES than students of other races. The ANOVA test confirms that these differences are significant because the F-statistic is huge (119). The presence of asterisks (*) also signifies significance.
After determining that at least two populations are significantly different, we can determine which two populations by running a post hoc test. Choosing which post hoc test best suits our needs will be dependent upon our initial data. If our original data has about the same variance (i.e. homogeneity of variance), we can use a test called Tukey’s HSD (for “honestly significant difference”). If not, we can use the Games Howell test. First, let’s go through a test to determine whether or not variances are homogenous.
Levene’s test for homogeneity of variance
In this test, the null and alternative hypotheses are:
H0: s12 = s22 = … = sk2
Ha: at least two population variances are significantly different.
How the statistic is calculated goes beyond the scope of this e-book; however, you’ll learn how to do this in R.
Because R is open source, people all over the world develop packages containing new functions that perform various statistical tests. For example, the “lawstat” package contains the levene.test() function, and you can install this package in order to run this test for homogeneity of variance.
First, download the package from cran.r-project.org/web/packages/lawstat/. The following code listing explains how to install the package in R and how to run Levene’s test using the ANOVA example of how SES differs by race.
Code Listing 12
> install.packages("lawstat") #installs the package into R --- Please select a CRAN mirror for use in this session --- > row.names(installed.packages()) #ensure that “lawstat” is listed as one of the packages currently installed > library(lawstat) #load the packages into R > levene.test(ses, race) #run Levene’s Test for homogeneity of variance modified robust Brown-Forsythe Levene-type test based on the absolute deviations from the median data: ses Test Statistic = 19.4668, p-value < 2.2e-16 |
Tip: If you’re not sure how to use a particular function in R, you can type a ? followed by the function name, and R will output information on each input of the function. For example, typing ?levene.test() and hitting ’enter’ will show you how to use this function.
According to this test, variances are not homogenous. Therefore, we would use the Games Howell test to determine which students have significantly different SES by race. First, let’s pretend the results of Levene’s test were not significant and go over how we would perform Tukey’s HSD in R.
Tukey’s HSD (variances are homogenous)
The TukeyHSD() test outputs the absolute differences between the means of each group (in this case, the difference between the mean SES), the lower and upper bounds of the 95% confidence interval for these differences, and the p-value (where p-values less than a indicate honestly significant differences).
Code Listing 13
> TukeyHSD(fit) Tukey multiple comparisons of means 95% family-wise confidence level Fit: aov(formula = ses ~ as.factor(race)) $`as.factor(race)` diff lwr upr p adj 1-0 -0.56137052 -0.83770881 -0.28503223 0.0000000 2-0 -0.19943500 -0.28097831 -0.11789169 0.0000000 3-0 -0.42032374 -0.49867291 -0.34197456 0.0000000 4-0 -0.65578712 -0.75465341 -0.55692083 0.0000000 5-0 -0.43597157 -0.53047888 -0.34146427 0.0000000 6-0 -0.16629343 -0.27444148 -0.05814539 0.0001191 2-1 0.36193552 0.07668733 0.64718372 0.0034779 3-1 0.14104678 -0.14330479 0.42539835 0.7669639 4-1 -0.09441660 -0.38509128 0.19625807 0.9627701 5-1 0.12539895 -0.16382216 0.41462006 0.8619244 6-1 0.39507709 0.10111583 0.68903835 0.0014499 3-2 -0.22088874 -0.32644573 -0.11533175 0.0000000 4-2 -0.45635212 -0.57791786 -0.33478639 0.0000000 5-2 -0.23653657 -0.35458451 -0.11848864 0.0000001 6-2 0.03314156 -0.09608570 0.16236883 0.9888601 4-3 -0.23546339 -0.35491007 -0.11601670 0.0000001 5-3 -0.01564783 -0.13151240 0.10021673 0.9996921 6-3 0.25403030 0.12679443 0.38126618 0.0000001 5-4 0.21981555 0.08919952 0.35043158 0.0000146 6-4 0.48949369 0.34869271 0.63029467 0.0000000 6-5 0.26967814 0.13190294 0.40745333 0.0000002 |
You can see from the results of the Tukey’s HSD test that the only races that do not have significantly different SES levels are between:
- Groups 3 and 1 (“Black or African American, non-Hispanic” and “Amer. Indian/Alaska Native, non-Hispanic”).
- Groups 4 and 1 (“Hispanic, no race specified” and “Amer. Indian/Alaska Native, non-Hispanic”).
- Groups 5 and 1 (“Hispanic, race specified” and “Amer. Indian/Alaska Native, non-Hispanic”).
- Groups 6 and 2 (“More than one race, non-Hispanic” and “Asian, Hawaii/Pac. Islander, non-Hispanic”).
- Groups 5 and 3 (“Hispanic, race specified” and “Black or African American, non-Hispanic”).
However, remember that the data did not pass our homogeneity of variance test, so let’s see what the Games Howell test has to say.
Games Howell (variances are not homogenous)
A package called “userfriendlyscience”[2] includes a convenient oneway() function that can output the results of a number of tests we specify in addition to the ANOVA results, including Levene’s test and the Games Howell test. Let’s run the oneway() function in R and include results of the Levene’s test to compare with the results we got earlier from the “lawstat” package.
Code Listing 14
> install.packages("userfriendlyscience") #installs the package into R --- Please select a CRAN mirror for use in this session --- > library(userfriendlyscience) #load the packages into R > oneway(ses, as.factor(race), posthoc="games-howell", levene=TRUE) #this will run ANOVA for the variable “ses” by the factor “race”, and additionally perform the Games Howell post hoc test and Levene’s test ### Oneway Anova for y=ses and x=as.factor(race) (groups: 0, 1, 2, 3, 4, 5, 6) Eta Squared: 95% CI = [0.07; 0.09], point estimate = 0.08 SS Df MS F Between groups (error + effect) 353.64 6 58.94 119.05 Within groups (error only) 4079.57 8240 0.5 p Between groups (error + effect) <.001 Within groups (error only) ### Levene's test: Levene's Test for Homogeneity of Variance (center = mean) Df F value Pr(>F) group 6 19.864 < 2.2e-16 *** 8240 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 ### Post hoc test: games-howell t df p 0:1 6.24 57.23 <.001 0:2 6.14 876.58 <.001 0:3 16.02 1058.23 <.001 0:4 19.25 561.13 <.001 0:5 12.40 613.47 <.001 0:6 4.91 462.84 <.001 1:2 3.82 70.29 .005 1:3 1.52 64.71 .731 1:4 0.99 71.89 .954 1:5 1.31 73.09 .845 1:6 4.15 71.62 .002 2:3 5.58 1434.84 <.001 2:4 10.10 1135.28 <.001 2:5 5.14 1191.55 <.001 2:6 0.74 1000.13 .990 3:4 5.75 984.95 <.001 3:5 0.37 1042.74 1.000 3:6 6.24 839.26 <.001 4:5 4.66 1009.76 <.001 4:6 10.60 867.93 <.001 5:6 5.74 914.77 <.001 |
We get the same results for ANOVA and Levene’s test using the oneway() function. We know from ANOVA that at least two groups are significantly different (i.e. at least two races have different SES levels), and we know from Levene’s test that there is not homogeneity of variance in SES between the different races.
Finally, it turns out that the Games Howell test gives us the same results as Tukey’s HSD.
Compare samples based on two factors
You just learned one-way ANOVA, which compares groups based on one independent variable (i.e. one factor). In our example, that factor was the location of the ad on the web page (top, middle, or sides). The dependent variable was the ad’s click-through rate.
Now let’s work with two-way ANOVA, which tests for significant differences based on two factors. For example, you may want to see how 2011 income differs by gender and whether or not getting good grades as a student differentiates income. Not only are you interested in the difference in income based on gender and grades, but also in a possible interaction effect between gender and grades (i.e. is the difference in income consistent between genders irrespective of grades received and is the difference in income consistent between grades irrespective of gender?).
There are three null hypotheses in two-way ANOVA:
- The means for Factor 1 are equal.
- The means for Factor 2 are equal.
- There is no interaction effect between Factor 1 and Factor 2.
Two-way ANOVA outputs an F-statistic for each hypothesis that determines whether we reject or fail to reject it. Calculating these statistics by hand gets very complicated, so we’ll simply review the basic principles before performing the analysis in R.
Each factor has a certain number of categories (e.g., in the NCES data, the factor “gender” has two categories: “male” and “female”; the factor “grades” has two categories: “Yes” and “No” in regard to whether or not the student was recognized for good grades). Let’s say Factor 1 has k categories and Factor 2 has q categories.
Each category contains a certain number of numeric values. Let’s use n to represent the number of values in Factor 1, where n1 is the number of values in Category 1 of Factor 1, n2 is the number of values in Category 2 of Factor 1, etc., through nk, which is the number of values in Category k of Factor 1.
Let’s use m to represent the number of values in Factor 2, where m1 is the number of values in Category 1 of Factor 2, m2 is the number of values in Category 2 of Factor 2, etc., through nq, which is the number of values in Category q of Factor 2.
Table 8: Two-way ANOVA has two factors (i.e. independent variables). Let’s say Factor 1 has k categories and n total values, and Factor 2 has q categories and m total values.
Factor 1 | Category 1 Category 2 … Category k | n1 values n2 values … nk values |
Factor 2 | Category 1 Category 2 … Category q | m1 values m2 values … mq values |
Our goal in two-way ANOVA is the same as with one-way ANOVA: we want to calculate measures of between-group variability and divide by a measure of error (within-group variability) to calculate our F-statistic. However, this time we’ll calculate two additional F-statistics: one for the second factor and one for the interaction between the two factors. We symbolize this interaction with a multiplication sign.
Let’s first calculate the sums-of-squares for Factor 1 and Factor 2 (SSbetween for each), the interaction of Factors 1 and 2 (SS1×2), the error (SSwithin), and SStotal.
We can make these calculations easier by organizing the means of each category in a table.
Table 9: The Mean Table organizes both the mean of each subset based on each factor and the marginal means (the mean of all values in each category of each factor). Marginal means are used to calculate between-group variability, while the means of each bucket (in a specific category of each factor) are used to calculate within-group variability.
Mean Table | |||||
|
Factor 1 (k categories) | |||||
Category 1 | Category 2 | Category 3 | Marginal Mean | ||
Factor 2 (q categories) | Category 1 |
|
|
|
|
Category 2 |
|
|
|
| |
Marginal Mean |
|
|
|
| |
![]() G can also be found by taking the weighted averages of the averages of each category, i.e. by choosing one of the factors, multiplying the average of each category by the sample size, and dividing the sum by N, where N = n1 + n2 + n3 = m1 + m2.
G can also be found by taking the weighted averages of the averages of each category, i.e. by choosing one of the factors, multiplying the average of each category by the sample size, and dividing the sum by N, where N = n1 + n2 + n3 = m1 + m2.
![]()
You can see we have six buckets of values associated with one of the categories from Factor 1 and one of the categories from Factor 2.
Now we can calculate the sums-of-squares for Factor 1 and Factor 2. SS1 is found by subtracting the grand mean ![]() G from the mean of each category from Factor 1, squaring each deviation, multiplying each squared deviation by the sample size for that category, and taking the sum. Similarly, SS2 is found by subtracting
G from the mean of each category from Factor 1, squaring each deviation, multiplying each squared deviation by the sample size for that category, and taking the sum. Similarly, SS2 is found by subtracting ![]() G from the mean of each category from Factor 2, etc.
G from the mean of each category from Factor 2, etc.

Note: These equations assume there are k categories for Factor 1 and q categories for Factor 2; however, Table 1 shows that k = 3 and q = 2.
To calculate the sum-of-squares for within-group variability (our error term), subtract the mean of each bucket (Factor 1 Category i and Factor 2 Category j) from each value in that bucket, square each deviation, and take the sum.

Note: Here’s a translation—this equation takes the first value in Factor 1, Category 1 and Factor 2, Category 1 (the top left box in the mean table) and subtracts the mean of all values in Factor 1, Category 1 and in Factor 2, Category 1, then continues this for every value in the data set. In other words, it sums the squared deviations of each value from the mean of all values in that same bucket (Factor 1 Category i and Factor 2 Category j). The above equation for SSwithin uses h to represent the h’th value of each category (xh,1,1 is the h’th value of Factor 1, Category 1 and Factor 2, Category 1).
The total sum-of-squares is the sum of the squared deviations of every value in the data set from the grand mean.
![]()
Because all the sums-of-squares sum to SStotal (SS1 + SS2 + SS1×2 + SSwithin = SStotal), we can calculate the sum-of-squares of the interaction (SS1×2) by subtracting SS1, SS2, and SSwithin from SStotal.
After finding each sum-of-squares, we need to know the degrees of freedom in order to calculate the mean square for each factor (MS1 and MS2), the error (MSwithin), and the interaction (MS1×2). The F-statistics will be each mean square divided by MSwithin.
Again, it helps to organize these calculations in a table.
Table 10: The ANOVA Table organizes the sums-of-squares (SS) for Factor 1, Factor 2, the interaction (Factor 1 × Factor 2), the error (within-group variability), and in total; the degrees of freedom (df); the mean squares (MS), which is SS/df; and the F-statistics (F), which tell us whether or not values of the dependent variable significantly differ by Factor 1, by Factor 2, or due to an interaction between the two.
SS | df | MS | F | |
Factor 1 | SS1 | df1 = k – 1 | MS1 = | MS1/MSwithin |
Factor 2 | SS2 | df2 = q – 1 | MS2 = | MS2/MSwithin |
Interaction | SS1×2 | df1 × df2 | MS1×2 = | MS1×2 / MSwithin |
Error | SSwithin | dfwithin = | MSwithin = | |
Total | SStotal = SS1 + SS2 + SS1 × SS2 + SSwithin | dftotal = df1 + df2 + N – 1 |
This should give you an idea of how we find each F-statistic, which, like one-way ANOVA, is the ratio of between-group variability to within-group variability.
Let’s now perform ANOVA on the NCES data using R with “income2011” as the dependent variable and “gender” and “grades” as the two factors or independent variables. We have coded subjects who are male as 0 and subjects who are female as 1. Subjects with bad grades are coded as 0 and subjects with good grades as 1.
Code Listing 15
> tapply(income2011, gender, mean) #find the mean of income2011 by each gender 0 1 30968.73 24013.91 > tapply(income2011, grades, mean) #find the mean of income2011 by whether or not the student was recognized for good grades 0 1 23995.63 30166.17 > income = aov(income2011 ~ as.factor(gender)*as.factor(grades)) #test whether or not gender, grades, and the interaction between gender and grades are significant > summary(income) #return the F statistics Df Sum Sq Mean Sq F value Pr(>F) as.factor(gender) 1 9.943e+10 9.943e+10 172.127 <2e-16 *** as.factor(grades) 1 9.928e+10 9.928e+10 171.875 <2e-16 *** as.factor(gender):as.factor(grades) 1 2.600e+09 2.600e+09 4.501 0.0339 * Residuals 8243 4.762e+12 5.777e+08 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 |
We can make a few observations using the tapply() function: males made an average of about $7,000 more than females, and students recognized for good grades made more than $6,000 annually in 2011.
When we perform ANOVA, we see that not only does income significantly differ by gender and whether or not students had good grades—there is also an interaction between these two factors, indicating that income is not consistent between grades when you separate students by gender. We can better understand this interaction effect by finding the mean income for each of the four groups (males who received good grades, females who received good grades, males who did not receive good grades, and females who did not receive good grades).
Code Listing 16
> tapply(income2011[grades=="0"], gender[grades=="0"], mean) #find the mean income in 2011 for students who did not receive good grades, separated by gender (again, for those who did not receive good grades) 0 1 28179.41 19272.01 > tapply(income2011[grades=="1"], gender[grades=="1"], mean) #find the mean income in 2011 for students who received good grades, separated by gender (again, for those who received good grades) 0 1 33998.32 27357.42 |
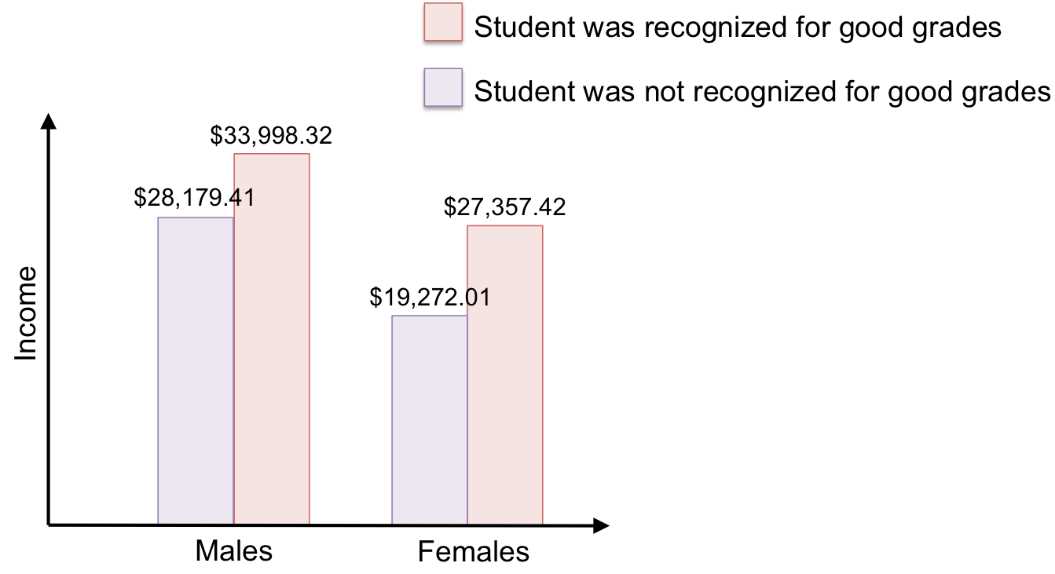
Figure 40: This bar graph visualizes the mean income for each group. Now we can see the interaction between gender and grades more clearly: females had a larger difference in income due to grades than did males.
Additional ANOVA information
Make sure you understand the data before accepting the results of ANOVA. For example, does your data have outliers? These can result in a Type I error (rejecting the null hypothesis when it is, in fact, true) or Type II error (failing to reject the null when there is, in fact, a significant difference) by pulling the mean toward it, so that the mean is not a good measure of center.
For ANOVA to have accurate results, the dependent variable should be normally distributed, have roughly equal sample sizes, and have roughly equal variances. Of course, this is not often the case, but there are methods to transform your data so that it no longer violates these assumptions. These additional tests and transformation methods are beyond the scope of our material, but there is a plethora of information online that describes what you can do for your data’s situation.
In the next lesson, you’ll learn statistical tests for tabulated data—determining whether or not frequencies (rather than specific values) differ significantly from what was expected.
- 1800+ high-performance UI components.
- Includes popular controls such as Grid, Chart, Scheduler, and more.
- 24x5 unlimited support by developers.