
The Kademlia Protocol Succinctly®

CHAPTER 5
Node Lookup
From the specification:
“The most important procedure a Kademlia participant must perform is to locate the k closest nodes to some given node ID. We call this procedure a node lookup. Kademlia employs a recursive algorithm for node lookups. The lookup initiator starts by picking a nodes from its closest non-empty k-bucket (or, if that bucket has fewer than a entries, it just takes the a closest nodes it knows of). The initiator then sends parallel, asynchronous FIND_NODE RPCS to the a nodes it has chosen, a is a system-wide concurrency parameter, such as 3.”
And:
“In the recursive step, the initiator resends the FIND_NODE to nodes it has learned about from previous RPCs. (This recursion can begin before all a of the previous RPCs have returned). Of the k nodes the initiator has heard of closest to the target, it picks a that it has not yet queried and resends the FIND_NODE RPC to them. Nodes that fail to respond quickly are removed from consideration until and unless they do respond. If a round of FIND_NODES fails to return a node any closer than the closest already seen, the initiator resends the FIND_NODE to all of the k closest nodes it has not already queried. The lookup terminates when the initiator has queried and gotten responses from the k closest nodes it has seen. When a = 1, the lookup algorithm resembles Chord’s in terms of message cost and the latency of detecting failed nodes. However, Kademlia can route for lower latency because it has the flexibility of choosing any one of k nodes to forward a request to.”
The idea here is to:
- Try really hard to return k close nodes.
- Contact other peers in parallel to minimize latency.
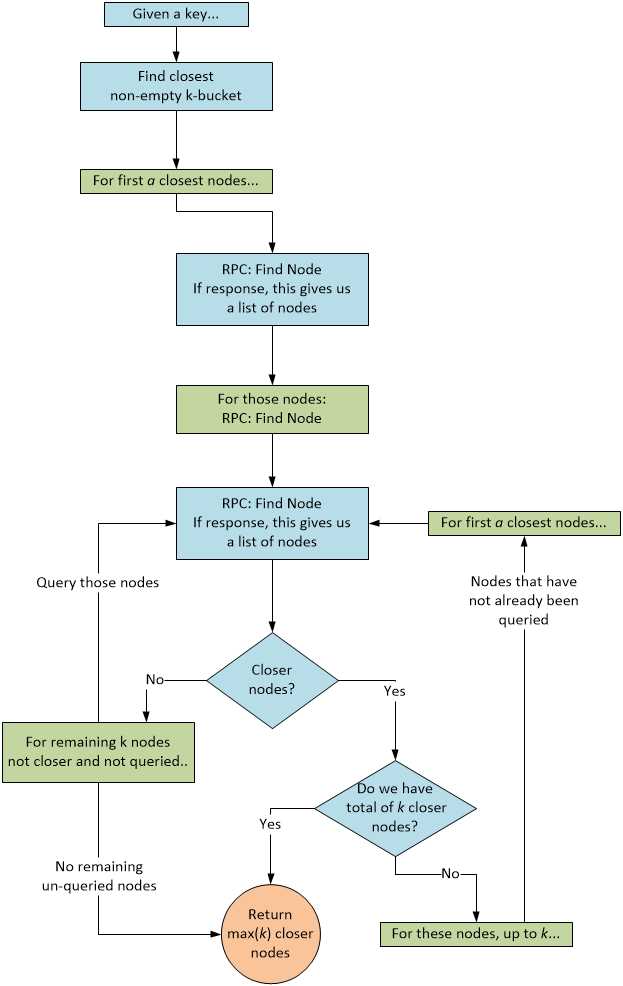
Figure 8: Node Lookup Algorithm
This looks complicated, but the implementation (shown later) is fairly straightforward.
Terminology: The lookup initiator: This is your own peer wanting to make a store or retrieve call to other peers. The node lookup is performed before you store or retrieve a value so that your peer has a reasonable.
“To store a (key,value) pair, a participant locates the k closest nodes to the key and sends them STORE RPCS.” Here the term “locates” actually means performing the lookup. Contrast with (from the spec): “To find a (key,value) pair, a node starts by performing a lookup to find the k nodes with IDs closest to the key,” in which the term “lookup” is specifically used.
We can see this implemented in Brian Muller’s Python code.
Code Listing 29: Find Neighbors Algorithm in Python
async def get(self, key): “““ Get a key if the network has it. Returns: :class:`None` if not found, the value otherwise. “““ dkey = digest(key) # if this node has it, return it if self.storage.get(dkey) is not None: return self.storage.get(dkey) node = Node(dkey) nearest = self.protocol.router.findNeighbors(node) ... async def set(self, key, value): “““ Set the given string key to the given value in the network. “““ self.log.debug("setting '%s' = '%s' on network" % (key, value)) dkey = digest(key) return await self.set_digest(dkey, value) async def set_digest(self, dkey, value): “““ Set the given SHA1 digest key (bytes) to the given value in the network. “““ node = Node(dkey) nearest = self.protocol.router.findNeighbors(node) ... |
Here, findNeighbors is the lookup algorithm described in the specification.
From the spec, what does “nodes that fail to respond quickly” mean? Particularly, the term “quickly”? This is an implementation-specific determination.
What if you, as a peer, don’t have peers in your own k-buckets? That shouldn’t happen (you should at least have the peer you are contacting), but if that peer only has you in its k-buckets, then there’s nothing to return.
From the spec, in “from its closest non-empty k-bucket,” what does “closest” mean? I am assuming here that it is the XOR distance metric, but then the question is, what do we use as the “key” for a bucket with a range of contacts? Since this is not defined, the implementation will search all the contacts across all buckets for the initial set of contacts that are closer. Also, the XOR distance computation means that we can’t just ping-pong in an outer search from the bucket containing the range in which the key resides. This better matches the other condition “or, if that bucket has fewer than a entries, it just takes the a closest nodes it knows of,” which implies searching for all a closest nodes across all buckets.
Again from the spec: “The lookup initiator starts by picking a nodes.” What does “picking” mean? Does this mean additionally sorting the contacts in the “closest bucket” also by closeness? It’s completely undefined.
If you want to try the “closest bucket” version, enable the #define TRY_CLOSEST_BUCKET, which is implemented like Code Listing 30.
Code Listing 30: Try Closest Bucket
KBucket bucket = FindClosestNonEmptyKBucket(key); // Not in spec -- sort by the closest nodes in the closest bucket. List<Contact> nodesToQuery = allNodes.Take(Constants.ALPHA).ToList(); |
Otherwise, the implementation simply gets the closest a contacts across all buckets.
Code Listing 31: Closest Contacts Across All Buckets
List<Contact> allNodes = node.BucketList.GetCloseContacts(key, |
However, this implementation, when testing with virtual nodes (where the system essentially knows every other node) effectively gets the k closest contacts because it’s searched all the buckets in virtual node space. So, if we want to exercise the algorithm, Code Listing 32 is better.
Code Listing 32: Closest Contacts For Unit Testing
List<Contact> allNodes = |
This actually leads to the next problem. In the initial acquisition of contacts as per the previous code, should contacts (I’m using “contact” and “node” rather interchangeably) that are closer at this point be added to the list of closer contacts? The spec doesn’t say not to, but it doesn’t explicitly say one should do this. Given that we pick only a contacts to start with, we definitely don’t have the k contacts that the lookup is expected to return, so I’m implementing this as described above—the a closest contacts we have are added to the “closer” list, and the a farther contacts we have are added to the “farther” list.
Code Listing 33: Adding Closer/Further Contacts to the Probed Contacts List
// Also not explicitly in spec: // Any closer node in the alpha list is immediately added to our closer contact list, closerContacts.AddRange(nodesToQuery.Where( fartherContacts.AddRange(nodesToQuery.Where( |
What do we do with the contacts outside of a? Given this (from the spec): “If a round of FIND_NODES fails to return a node any closer than the closest already seen, the initiator resends the FIND_NODE to all of the k closest nodes it has not already queried,” does it apply to the first query of a nodes, or only to the set of nodes returned after the query? I’m going to assume that it applies to the remainder of the a nodes not queried in the first query, which will be a maximum of k-a contacts.
The spec says this: “Most operations are implemented in terms of the above lookup procedure.” Which operations, and when? We’ll have to address this later.
The concept of closeness
From the spec: “Many of Kademlia’s benefits result from its use of a novel XOR metric for distance between points in the key space. XOR is symmetric, allowing Kademlia participants to receive lookup queries from precisely the same distribution of nodes contained in their routing tables.”
Therefore, the distance between a node and a key is the node ID XORed with the key. Unfortunately, an XOR distance metric is not amenable to a pre-sorted list of IDs. The resulting “distance” computation can be very different for two keys when XOR’d with the contact list. As described on Stack Overflow:[12]
“The thing is that buckets don’t have to be full, and if you want to send, let’s say, 20 nodes in a response, a single bucket will not suffice. So you must traverse the routing table (either sorted based on your own node ID or by the natural distance) in ascending distance (XOR) order relative to the target key to visit multiple buckets. Because the XOR distance metric folds at each bit-carry (XOR == carry-less addition), it does not map nicely to any routing table layout. In other words, visiting the nearest buckets won’t do...I figure that many people simply iterate over the whole routing table, because for regular nodes it will only contain a few dozen buckets at most, and a DHT node does not see much traffic, so it only has to execute this operation a few times per second. If you implement this in a dense, cache-friendly data structure, then the lion’s share might actually be the memory traffic and not the CPU instructions doing a few XORs and comparisons.
I.e. a full table scan is just easy to implement.”
The author of that post provides an implementation[13] that doesn’t require a full table scan, but in my implementation, we’ll just do a full scan of the bucket list contacts.
Implementation
Let’s start with a baseline implementation that for the moment:
- Doesn’t deal with the issue of parallelism.
- Doesn’t deal with querying only a nodes—we set a to the constant k for the moment.
- At the moment, we’re also ignoring the fact that this algorithm is the same for node lookup as it is for value lookup.
This simplifies the implementation so that we can provide some unit tests for the basic algorithm, then add the parallelism and a concept later, and our unit tests should still pass. Also, the methods here are all marked as virtual in case you want to override the implementation. First, some helper methods:
Code Listing 34: FindClosestNonEmptyKBucket
public virtual KBucket FindClosestNonEmptyKBucket(ID key) Validate.IsTrue<NoNonEmptyBucketsException>(closest != null, return closest; } |
Code Listing 35: GetClosestNodes
public List<Contact> GetClosestNodes(ID key, KBucket bucket) |
Code Listing 36: RpcFindNodes
public dht?.HandleError(timeoutError, contact); return (newContacts, null, null); |
Note that in this code we have a method for handling timeouts and other errors, which we’ll describe later.
Code Listing 37: GetCloserNodes
public bool GetCloserNodes( ID key, Contact nodeToQuery, Func< List<Contact> closerContacts, List<Contact> fartherContacts, out string val, out Contact foundBy) { // As in, peer's nodes: // Exclude ourselves and the peers we're contacting (closerContacts and var (contacts, cFoundBy, foundVal) = rpcCall(key, nodeToQuery); val = foundVal; foundBy = cFoundBy; List<Contact> peersNodes = contacts. ExceptBy(node.OurContact, c => c.ID). ExceptBy(nodeToQuery, c => c.ID). Except(closerContacts). Except(fartherContacts).ToList(); // Null continuation is a special case primarily for unit testing when we have var nearestNodeDistance = nodeToQuery.ID ^ key; lock (locker) { closerContacts. AddRangeDistinctBy(peersNodes. Where(p => (p.ID ^ key) < nearestNodeDistance), (a, b) => a.ID == b.ID); } lock (locker) { fartherContacts. AddRangeDistinctBy(peersNodes. Where(p => (p.ID ^ key) >= nearestNodeDistance), (a, b) => a.ID == b.ID); } return val != null; } |
Note that we always exclude our own node and the nodes we’re contacting. Also note the lock statements to synchronize manipulating the contact list.
Also:
Func<ID, Contact, (List<Contact> contacts, Contact foundBy, string val)> rpcCall
This parameter handles calling either FindNode or FindValue, which we’ll discuss later.
This flowchart all comes together in the Lookup method in the Router class. This is where the complexity of the flowchart is implemented, so there’s a lot here. Remember that the rpcCall is calling either a FindNode or a FindValue, so some of the logic here has to figure out to exit the lookup if a value is found. There’s extensive use of tuples here as well, which hopefully makes the code clearer! Lastly, this method is actually an abstract method in a base class because later on, we’ll see implementing this algorithm as a parallel “find” (something the spec talks about), but for now, Code Listing 38 shows the nonparallel implementation.
Code Listing 38: The Lookup Algorithm
public override (bool found, List<Contact> contacts, Contact foundBy, string val) ID key, Func<ID, Contact, (List<Contact> contacts, Contact foundBy, string val)> rpcCall, bool giveMeAll = false) { bool haveWork = true; List<Contact> ret = new List<Contact>(); List<Contact> contactedNodes = new List<Contact>(); List<Contact> closerContacts = new List<Contact>(); List<Contact> fartherContacts = new List<Contact>(); List<Contact> closerUncontactedNodes = new List<Contact>(); List<Contact> fartherUncontactedNodes = new List<Contact>(); #if DEBUG List<Contact> allNodes = #else // This is a bad way to get a list of close contacts with virtual nodes because List<Contact> allNodes = #endif List<Contact> nodesToQuery = allNodes.Take(Constants.ALPHA).ToList(); closerContacts.AddRange(nodesToQuery.Where( fartherContacts.AddRange(nodesToQuery.Where( // The remaining contacts not tested yet can be put here. fartherContacts.AddRange(allNodes.Skip(Constants.ALPHA). // We're about to contact these nodes. contactedNodes.AddRangeDistinctBy(nodesToQuery, (a, b) => a.ID == b.ID); // Spec: The initiator then sends parallel, asynchronous FIND_NODE RPCS to the a var queryResult = if (queryResult.found) { #if DEBUG // For unit testing. CloserContacts = closerContacts; FartherContacts = fartherContacts; #endif return queryResult; } // Add any new closer contacts to the list we're going to return. ret.AddRangeDistinctBy(closerContacts, (a, b) => a.ID == b.ID); // Spec: The lookup terminates when the initiator has queried and received while (ret.Count < Constants.K && haveWork) { closerUncontactedNodes = closerContacts.Except(contactedNodes).ToList(); fartherUncontactedNodes = fartherContacts.Except(contactedNodes).ToList(); bool haveCloser = closerUncontactedNodes.Count > 0; bool haveFarther = fartherUncontactedNodes.Count > 0; haveWork = haveCloser || haveFarther; // Spec: Of the k nodes the initiator has heard of closest to the target... if (haveCloser) { // Spec: ...it picks a that it has not yet queried and resends the var newNodesToQuery = closerUncontactedNodes.Take(Constants.ALPHA).ToList(); // We're about to contact these nodes. contactedNodes.AddRangeDistinctBy(newNodesToQuery, (a, b) => a.ID == b.ID); queryResult = if (queryResult.found) { #if DEBUG // For unit testing. CloserContacts = closerContacts; FartherContacts = fartherContacts; #endif return queryResult; } } else if (haveFarther) { var newNodesToQuery = fartherUncontactedNodes.Take(Constants.ALPHA).ToList(); // We're about to contact these nodes. contactedNodes.AddRangeDistinctBy(fartherUncontactedNodes, queryResult = if (queryResult.found) { #if DEBUG // For unit testing. CloserContacts = closerContacts; FartherContacts = fartherContacts; #endif return queryResult; } } } #if DEBUG // For unit testing. CloserContacts = closerContacts; FartherContacts = fartherContacts; #endif // Spec (sort of): Return max(k) closer nodes, sorted by distance. // For unit testing, giveMeAll can be true so that we can match against our return ( } |
This algorithm is iteration, not recursion, as the specification states. Every implementation I’ve seen uses iteration.
Here’s an extension method that is used.
Code Listing 39: AddRangeDistinctBy
public static void AddRangeDistinctBy<T>( { src.ForEach(item => { // no items in the list must match the item. if (target.None(q => equalityComparer(q, item))) { target.Add(item); } }); } |
Unit tests
Before getting into unit tests, we need to be able to create virtual nodes, which means implementing a minimal VirtualProtocol:
Code Listing 40: Virtual Node
public class VirtualProtocol : IProtocol /// For unit testing with deferred node setup. /// </summary> public VirtualProtocol(bool responds = true) { Responds = responds; } /// <summary> /// Register the in-memory node with our virtual protocol. /// </summary> public VirtualProtocol(Node node, bool responds = true) { Node = node; Responds = responds; } { return new RpcError() { TimeoutError = !Responds }; } /// <summary> /// Get the list of contacts for this node closest to the key. /// </summary> public (List<Contact> contacts, RpcError error) FindNode(Contact sender, ID key) { return (Node.FindNode(sender, key).contacts, NoError()); } /// <summary> /// Returns either contacts or null if the value is found. /// </summary> public (List<Contact> contacts, string val, RpcError error) { var (contacts, val) = Node.FindValue(sender, key); return (contacts, val, NoError()); } /// <summary> /// Stores the key-value on the remote peer. /// </summary> public RpcError Store( { Node.Store(sender, key, val, isCached, expTimeSec); return NoError(); } protected RpcError NoError() { return new RpcError(); } } |
Notice that for unit testing, we have the option to simulate a nonresponding node.
We also have to implement FindNode in the Node class (the other methods we’ll implement later).
Code Listing 41: FindNode
public (List<Contact> contacts, string val) FindNode(Contact sender, ID key) { Validate.IsFalse<SendingQueryToSelfException>(sender.ID == ourContact.ID, SendKeyValuesIfNewContact(sender); bucketList.AddContact(sender); // Exclude sender. var contacts = bucketList.GetCloseContacts(key, sender.ID); return (contacts, null); } |
Note that this call attempts to add the sender as a contact, which either adds (maybe) the contact to the recipient’s bucket list or updates the contact information. If the contact is new, any key-values that are “closer” to the new peer are sent. This is an important aspect of the Kademlia algorithm: peers that are “closer” to the stored key-values get those key-values so that the efficiency of lookups to find a key-value is improved.
We also need an algorithm for finding close contacts across the recipient’s bucket range.
Code Listing 42: GetCloseContacts
/// <summary> /// Brute force distance lookup of all known contacts, sorted by distance, then we /// </summary> /// <param name="toFind">The ID for which we want to find close contacts.</param> /// <param name="exclude">The ID to exclude (the requestor's ID)</param> public List<Contact> GetCloseContacts(ID key, ID exclude) { lock (this) { var contacts = buckets. SelectMany(b => b.Contacts). Where(c => c.ID != exclude). Select(c => new { contact = c, distance = c.ID ^ key }). OrderBy(d => d.distance). Take(Constants.K); return contacts.Select(c => c.contact).ToList(); } } |
This tests the sorting and the maximum number of contacts returned limit. Note that it’s probably not the most ideal situation that I’m using all random IDs; however, to ensure consistent unit testing, we seed the random number generator with the same value in DEBUG mode.
Code Listing 43: Debug Mode Seeding of Random Values
#if DEBUG public static Random rnd = new Random(1); #else private static Random rnd = new Random(); #endif |
GetCloseContacts unit test
Finally, we can implement the “get close contacts” unit test.
Code Listing 44: GetCloseContactsOrderedTest()
[TestMethod] public void GetCloseContactsOrderedTest() { Contact sender = new Contact(null, ID.RandomID); Node node = new Node(new Contact(null, ID.RandomID), new VirtualStorage()); List<Contact> contacts = new List<Contact>(); // Force multiple buckets. 100.ForEach(() => contacts.Add(new Contact(null, ID.RandomID))); contacts.ForEach(c => node.BucketList.AddContact(c)); ID key = ID.RandomID; // Pick an ID List<Contact> closest = node.FindNode(sender, key).contacts; Assert.IsTrue(closest.Count == Constants.K, "Expected K contacts to be returned."); // The contacts should be in ascending order with respect to the key. var distances = closest.Select(c => c.ID ^ key).ToList(); var distance = distances[0]; // Verify distances are in ascending order: distances.Skip(1).ForEach(d => { Assert.IsTrue(distance < d, "Expected contacts ordered by distance."); distance = d; }); // Verify the contacts with the smallest distances were returned from all var lastDistance = distances[distances.Count - 1]; var others = node.BucketList.Buckets.SelectMany( Assert.IsTrue(others.Count() == 0, } |
NoNodesToQuery unit test
This test simply verifies that we get no new nodes to query given that all the nodes we’re contacting are already being contacted.
Code Listing 45: NoNodes ToQuery unit test
/// <summary> /// Given that all the nodes we’re contacting are nodes *being* contacted, /// the result should be no new nodes to contact. /// </summary> [TestMethod] public void NoNodesToQueryTest() { // Setup router = new Router(new Node(new Contact(null, ID.Mid), new VirtualStorage())); nodes = new List<Node>(); 20.ForEach((n) => nodes.Add(new Node(new Contact(null, // Fixup protocols: nodes.ForEach(n => n.OurContact.Protocol = new VirtualProtocol(n)); // Our contacts: nodes.ForEach(n => router.Node.BucketList.AddContact(n.OurContact)); // Each peer needs to know about the other peers except of course itself. nodes.ForEach(n => nodes.Where(nOther => nOther != n). // Select the key such that n ^ 0 == n // This ensures that the distance metric uses only the node ID, which makes for key = ID.Zero; contactsToQuery = router.Node.BucketList.Buckets[0].Contacts; closerContacts = new List<Contact>(); fartherContacts = new List<Contact>(); contactsToQuery.ForEach(c => { router.GetCloserNodes(key, c, router.RpcFindNodes, }); Assert.IsTrue(closerContacts.ExceptBy(contactsToQuery, c=>c.ID).Count() == 0, Assert.IsTrue(fartherContacts.ExceptBy(contactsToQuery, c=>c.ID).Count() == 0, } |
Lookup unit test
Ironically, there really is no alternative way of getting these nodes, particularly with regards to the while loop in the Lookup method. So without beating my head over the issue, I implemented this test in Code Listing 46.
Code Listing 46: Lookup Unit Test
public void LookupTest() { // Seed with different random values 100.ForEach(seed => { ID.rnd = new Random(seed); Setup(); List<Contact> closeContacts = List<Contact> contactedNodes = new List<Contact>(closeContacts); // Is the above call returning the correct number of close contacts? // The unit test for this is sort of lame. We should get at least GetAltCloseAndFar( Assert.IsTrue(closeContacts.Count >= closerContactsAltComputation.Count, // Technically, we can’t even test whether the contacts returned // We can overcome this by eliminating the Take in the return of router.Lookup(). closerContactsAltComputation.ForEach(c => }); } |
The setup for this unit test is complex.
Code Listing 47: Lookup Setup
protected void Setup() { // Setup router = new Router( nodes = new List<Node>(); 100.ForEach(() => { Contact contact = new Contact(new VirtualProtocol(), ID.RandomID); Node node = new Node(contact, new VirtualStorage()); ((VirtualProtocol)contact.Protocol).Node = node; nodes.Add(node); }); // Fixup protocols: nodes.ForEach(n => n.OurContact.Protocol = new VirtualProtocol(n)); // Our contacts: nodes.ForEach(n => router.Node.BucketList.AddContact(n.OurContact)); // Each peer needs to know about the other peers except of course itself. nodes.ForEach(n => nodes.Where(nOther => nOther != n). // Pick a random bucket, or bucket where the key is in range, otherwise key = ID.RandomID; // Pick an ID // DO NOT DO THIS: // List<Contact> nodesToQuery = router.Node.BucketList.GetCloseContacts( contactsToQuery = // or: // contactsToQuery = closerContacts = new List<Contact>(); fartherContacts = new List<Contact>(); closerContactsAltComputation = new List<Contact>(); fartherContactsAltComputation = new List<Contact>(); theNearestContactedNode = contactsToQuery.OrderBy(n => n.ID ^ key).First(); distance = theNearestContactedNode.ID.Value ^ key.Value; } |
Furthermore, we use a different implementation for acquiring closer and farther contacts, so that we can verify the algorithm under test. Code Listing 48 shows the alternate implementation.
Code Listing 48: Alternate Implementation for Getting Closer and Farther Nodes
protected void GetAltCloseAndFar( { // For each node (ALPHA == K for testing) in our bucket (nodesToQuery) we're foreach (Contact contact in contactsToQuery) { // Find the node we're contacting: Node contactNode = nodes.Single(n => n.OurContact == contact); // Close contacts except ourself and the nodes we're contacting. // Note that of all the contacts in the bucket list, many of the k returned // by the GetCloseContacts call are contacts we're querying, so they are var closeContactsOfContactedNode = contactNode. BucketList. GetCloseContacts(key, router.Node.OurContact.ID). ExceptBy(contactsToQuery, c => c.ID.Value); foreach (Contact closeContactOfContactedNode in closeContactsOfContactedNode) { // Which of these contacts are closer? if ((closeContactOfContactedNode.ID ^ key) < distance) { closer.AddDistinctBy(closeContactOfContactedNode, c => c.ID.Value); } // Which of these contacts are farther? if ((closeContactOfContactedNode.ID ^ key) >= distance) { farther.AddDistinctBy(closeContactOfContactedNode, c => c.ID.Value); } } } } |
SimpleCloserContacts test
This test, and the next one, exercise the part of the Lookup algorithm before the while loop. Note how the bucket and IDs are set up.
Code Listing 49: SimpleAllCloserContactsTest
[TestMethod] public void SimpleAllCloserContactsTest() { // Setup // By selecting our node ID to zero, we ensure that all distances of router = new Router(new Node(new Contact(null, ID.Max), new VirtualStorage())); nodes = new List<Node>(); Constants.K.ForEach((n) => nodes.Add(new Node(new Contact(null, // Fixup protocols: nodes.ForEach(n => n.OurContact.Protocol = new VirtualProtocol(n)); // Our contacts: nodes.ForEach(n => router.Node.BucketList.AddContact(n.OurContact)); // Each peer needs to know about the other peers except of course itself. nodes.ForEach(n => nodes.Where(nOther => nOther != n). // Select the key such that n ^ 0 == n // This ensures that the distance metric uses only the node ID, which makes key = ID.Zero; contactsToQuery = router.Node.BucketList.Buckets[0].Contacts; var contacts = router.Lookup(key, router.RpcFindNodes, true).contacts; Assert.IsTrue(contacts.Count == Constants.K, "Expected k closer contacts."); Assert.IsTrue(router.CloserContacts.Count == Constants.K, Assert.IsTrue(router.FartherContacts.Count == 0, } |
SimpleFartherContacts test
Again, note how the bucket and IDs are set up in Code Listing 50.
Code Listing 50: SimpleAllFartherContactsTest
/// <summary> /// Creates a single bucket with node IDs 2^i for i in [0, K) and /// 1. use a key with ID.Value == 0 to that distance computation is an /// 2. use an ID.Value == 0 for our node ID so all other nodes are farther. /// </summary> [TestMethod] public void SimpleAllFartherContactsTest() { // Setup // By selecting our node ID to zero, we ensure that all distances of other router = new Router(new Node(new Contact(null, ID.Zero), new VirtualStorage())); nodes = new List<Node>(); Constants.K.ForEach((n) => nodes.Add(new Node(new Contact(null, // Fixup protocols: nodes.ForEach(n => n.OurContact.Protocol = new VirtualProtocol(n)); // Our contacts: nodes.ForEach(n => router.Node.BucketList.AddContact(n.OurContact)); // Each peer needs to know about the other peers except of course itself. nodes.ForEach(n => nodes.Where(nOther => nOther != n). // Select the key such that n ^ 0 == n // This ensures that the distance metric uses only the node ID, which makes key = ID.Zero; var contacts = router.Lookup(key, router.RpcFindNodes, true).contacts; Assert.IsTrue(contacts.Count == 0, "Expected no closer contacts."); Assert.IsTrue(router.CloserContacts.Count == 0, Assert.IsTrue(router.FartherContacts.Count == Constants.K, } |
- 1800+ high-performance UI components.
- Includes popular controls such as Grid, Chart, Scheduler, and more.
- 24x5 unlimited support by developers.