
BI Solutions Using SSAS Tabular Model Succinctly®

CHAPTER 3
Learning DAX
Data Analysis Expressions (DAX) is the language used to define calculations in the tabular data model. DAX is also the query language used by the client reporting tools to query the tabular data model. In this chapter we will start with basics of DAX (syntax, operators, data types, and evaluation context) and later learn DAX functions.
A DAX query reference contains a number of functions that operate on the column of the table or table itself and evaluates to either a scalar constant or returns a table as well.
DAX syntax
When DAX is used to define calculated columns or measures, the formula always starts with an equal (=) sign. In DAX syntax, the column names of the tables are always referenced within square brackets [ ] and the column names are preceded by the name of the table.
For example, in the previous chapter, we defined the calculated “Name” column in the Employee table using the following formula:
=Employee[FirstName] & " " & Employee[MiddleName] & " " & Employee[LastName] |
We defined measures in the data model using the following formula:
Sales:=SUM(ResellerSales[SalesAmount]) |
In these examples, we see that a formula starts with an equal sign and all the columns are referenced as <table-name>[<column-name>].
When DAX is used as a query language to query the tabular data model, the syntax appears as:
DEFINE { MEASURE <table>[<col>] = <expression> }] EVALUATE <Table Expression> [ORDER BY {<expression> [{ASC | DESC}]} [, …] [START AT {<value>|<parameter>} [, …]] ] |
DAX as a query language always starts with the EVALUATE keyword followed by an expression, which returns a table.
DAX operators
There are four different types of calculation operators supported by DAX: arithmetic, comparison, text concatenation, and logical.
Arithmetic Operators
Operator | Operation |
+ | Add |
- | Subtract |
* | Multiply |
/ | Divide |
^ | Exponentiation |
Comparison Operators
Operator | Operation |
= | Equal to |
> | Greater than |
< | Less than |
>= | Greater than or equal to |
<= | Less than or equal to |
<> | Not equal to |
Text Operators
Operator | Operation |
& | Concatenation |
Logical Operators
Operator | Operation |
&& | Logical AND |
|| | Logical OR |
DAX operators have the following order of precedence:
- ^
- – (Sign operator for negative values)
- * /
- ! (NOT Operator)
- + -
- &
- <, >, >=, <=, =, <>
DAX data types
The following data types are supported. When you import data or use a value in a formula, even if the original data source contains a different data type, the data is converted to one of the following data types. Values that result from formulas also use these data types.
Data type in model | Data type in DAX | Description |
|---|---|---|
Whole number | A 64-bit (eight bytes) integer value | Numbers that have no decimal places. Integers can be positive or negative numbers, but must be whole numbers between -9,223,372,036,854,775,808 (-2^63) and 9,223,372,036,854,775,807 (2^63-1). |
Decimal number | A 64 bit (eight-bytes) real number | Real numbers are numbers that can have decimal places. Real numbers cover a wide range of values: |
Boolean | Boolean | Either a True or False value. |
Text | String | A Unicode character data string. Can be strings, numbers, or dates represented in a text format. |
Date | Date/time | Dates and times in an accepted date-time representation. |
Currency | Currency | Currency data type allows values between ‑922,337,203,685,477.5808 and 922,337,203,685,477.5807 with four decimal digits of fixed precision. |
N/A | Blank | A blank is a data type in DAX that represents and replaces SQL nulls. You can create a blank by using the BLANK function, and test for blanks by using the logical function, ISBLANK. |
In addition, DAX uses a table data type. This data type is used by DAX in many functions, such as aggregations and time intelligence calculations. Some functions require a reference to a table; other functions return a table that can then be used as input to other functions. In some functions that require a table as input, you can specify an expression that evaluates to a table. For some functions, a reference to a base table is required.
Evaluation context
DAX formulas or expressions are always evaluated in one of the following contexts:
- Row context
- Query context
- Filter context
Row context
When a DAX formula is evaluated in row context, the expression is evaluated for each row of the column referenced by the expression. Calculated column expressions are always evaluated in row context.
For example, in our data model we defined the calculated column using the following DAX formula.
=Employee[FirstName] & " " & Employee[MiddleName] & " " & Employee[LastName] |
This DAX formula is evaluated for each row of the Employee table, and hence is evaluated under the row context of the Employee table.
Query context
When a DAX formula is evaluated in the context of a query, the expression is evaluated by applying the filters defined for that query.
For example:

- Dynamically changing query
In this Excel report, as the user clicks on various values of the Country slicer, the DAX query for the pivot table dynamically changes to reflect the filter value selected by the user. In other words, the DAX query is said to be evaluated in the query context.
Filter context
When a DAX formula is evaluated in filter context, the filters defined in the formula override any in the query context or row context. For example, in our data model, we define the following calculated measure:
FY04 Sales:=CALCULATE(SUM(ResellerSales[SalesAmount]),'Date'[FiscalYear]=2004) |
This formula contains a filter for the fiscal year 2004, so it will always be evaluated under this filter context.
If the measure “FY04 Sales” is used in the Excel report with the slicer setting for fiscal year, the slicer selection does not affect the FY04 Sales measure value because the measure is evaluated in filter context, which overrides the query context.

- Filter context in Excel
DAX functions
The DAX language contains a rich set of functions, which makes it a powerful language for analytics and reporting. These functions are categorized into the following:
- Aggregation functions
- Date and time functions
- Filter functions
- Information functions
- Logical functions
- Mathematical and trigonometric functions
- Statistical functions
- Text functions
- Time intelligence functions
Discussing each function in the DAX query reference is beyond the scope of this book; however, we will discuss some commonly used functions from each category.
Aggregation functions
Aggregation functions are used for aggregating the columns. These are primarily useful in defining measures.
The following is a list of aggregation functions available in DAX along with a brief description of each.
Function | Use |
|---|---|
AVERAGE | Returns the average (arithmetic mean) of all the numbers in a column. |
AVERAGEA | Returns the average (arithmetic mean) of all the values in a column. Handles text and non-numeric values. |
AVERAGEX | Averages a set of expressions evaluated over a table. |
MAX | Returns the largest numeric value in a column. |
MAXX | Returns the largest value from a set of expressions evaluated over a table. |
MIN | Returns the smallest numeric value in a column. |
MINX | Returns the smallest value from a set of expressions evaluated over a table. |
SUM | Adds all the numbers in a column. |
SUMX | Returns the sum of a set of expressions evaluated over a table. |
COUNT | Counts the number of numeric values in a column. |
COUNTA | Counts the number of values in a column that are not empty. |
COUNTAX | Counts a set of expressions evaluated over a table. |
COUNTBLANK | Counts the number of blank values in a column. |
COUNTX | Counts the total number of rows in a table. |
COUNTROWS | Counts the number of rows returned from a nested table function, such as the filter function. |
Aggregation functions are pretty self-explanatory and simple to use. In the set of functions listed in the previous table, there are variations of the aggregation functions with an “X” suffix, for example, SUMX and AVERAGEX. These functions are used to aggregate an expression over a table or an expression that returns a table. For example, the syntax for the SUMX is:
SUMX(<table>, <expression>) |
We can define a calculated measure as follows.
France Sales:=SUMX(FILTER('ResellerSales',RELATED(SalesTerritory[Country])="France"),ResellerSales[SalesAmount]) |
In this formula, the FILTER function first filters the Reseller Sales for France, and later THE SUMX function aggregates the SalesAmount for the sales transactions in France.
The X suffix aggregate function gives us the flexibility to aggregate over a set of rows (or a table) returned from the expression.
Some of the aggregate functions listed in the previous table have an “A” suffix (AVERAGEA, COUNTA). The “A” suffix functions aggregate columns or data with non-numeric data types. All other aggregate functions can aggregate only numeric data types. For example:
COUNTA(<column>) |
When the function does not find any rows to count, the function returns a blank. When there are rows, but none of them meet the specified criteria, then the function returns 0.
Regions:=COUNTA(SalesTerritory[Region]) |
The previous DAX formula counts the regions covered by the AdventureWorks Sales Territory, which can used in the following report.

- Using an aggregate formula for a non-numeric data type
Date and time functions
In a data warehouse or dimension model, date and time dimensions are conformed dimensions since they are used in all data marts for analyzing measures across dates and times. The Date dimension defined in the data model should have as many columns or attributes as possible (for example, Day, Month, DayOfWeek, MonthOfYear) to give end users the flexibility to identify trends in the data over time.
To support analysis across date and time dimensions, and to extract various attributes from Date columns, we have the following date and time functions.
Function | Use |
|---|---|
DATE | Returns the specified date as a datetime. |
DATEVALUE | Converts a text date value to a date in datetime format. |
DAY | Returns the day of the month as a numeric value. |
EDATE | Returns the date as a number of months before or after the start date. |
EOMONTH | Returns the date of the last day of the month. |
HOUR | Returns the hour as a numeric value from 0 to 23. |
MINUTE | Returns the minute as a numeric value from 0 to 59. |
MONTH | Returns the month as a numeric value from 1 to 12. |
NOW | Returns the current date and time. |
TIME | Converts hours, minutes, and seconds to a time value in a datetime format. |
TIMEVALUE | Converts a text date value to a time in datetime format. |
TODAY | Returns the current date. |
WEEKDAY | Returns the current day of the week as a numeric value between 1 (Sunday) and 7 (Saturday). |
WEEKNUM | Returns the week number of the year. |
YEAR | Returns the current year of a date, with integer values between 1900 and 9999. |
YEARFRAC | Calculates the fraction of the year represented by the number of days between two dates. |
The functions DAY, MONTH, and YEAR are used to extract the day, month, and year respectively from the date values. For example:
YEAR(<date>) , Day(<date>), Month(<date>) =YEAR('Date'[FullDateAlternateKey]) |

- Using date and time functions
Filter functions
Filter functions are another commonly used set of functions, which we have already used in some prior examples. As we slice and dice the measures across the various columns of the table, we filter the data for those values of the columns, which is achieved by using filter functions.
The following table lists the available filter functions.
Function | Use |
|---|---|
CALCULATE(<expression>,<filter1>,<filter2>…) | Evaluates an expression in a context that is modified by the specified filters in the function. |
CALCULATETABLE(<expression>,<filter1>,<filter2>…) | Evaluates a table expression in a context that is modified by the specified filters in the function. |
RELATED(<column>) | Returns a related value from another related table. |
RELATEDTABLE(<TableName>) | Evaluates a table expression based on the filter context. |
ALL({<table>|<column>[, <column>[, <column>[,…]]]}) | Returns all the rows in a table, or all the values in a column, ignoring any filters that might have been applied. |
ALLEXCEPT(<table>,<column>[,<column>[,…]]) | Removes all context filters in the table except filters that have been applied to the specified columns. |
ALLNOBLANKROW(<table>|<column>) | From the parent table of a relationship, returns all rows but the blank row, or all distinct values of a column but the blank row, disregarding context filters. |
ALLSELECTED([<tablename>|<columnname>) | Gets the context that represents all rows and columns in the query while maintaining filter and row contexts. |
DISTINCT(<column>) | Returns a table consisting of one column with distinct values from the column specified. |
FILTER(<table>,<filter>) | Returns a table that represents a subset of another table or expression. |
FILTERS(<columnName>) | Returns the values that are directly applied as filters to columnName. |
HASONEFILTER(<columnName>) | Returns TRUE when the number of directly filtered values on columnName is one; otherwise returns FALSE. |
HASONEVALUE(<columnName>) | Returns TRUE when the filtered context for columnName has one distinct value only; otherwise returns FALSE. |
ISCROSSFILTERED(<columnName>) | Returns TRUE when columnName or another column in the same or related table is being filtered. |
ISFILTERED(<columnName>) | Returns TRUE when columnName is being filtered; otherwise returns FALSE. |
EARLIER(<column>,<number>) | Used for nested calculations where there is a need to use a certain value as an input and produce calculations based on that input. |
EARLIEST(<column>) | Returns the current value of the specified column in an outer evaluation pass of the specified column. |
VALUES(<column>) | Returns a one-column table containing the distinct values from the specified column. |
Although the previous functions are categorized as filter functions, each is unique in the way it filters data. Let us discuss some of the filter functions here.
CALCULATE function
The CALCULATE function is one of the most commonly used functions used to evaluate an expression by applying various filters. Filters defined in the CALCULATE function override the query context in the client tools. For example:
CALCULATE( <expression>, <filter1>, <filter2>… ) |
Previously, we defined a calculated measure as FY04 Sales, which uses the CALCULATE function to calculate the sales for the fiscal year 2004:
FY04 Sales:=CALCULATE(SUM(ResellerSales[SalesAmount]),'Date'[FiscalYear]=2004) |
In the previous DAX formula, the sum of the SalesAmount is evaluated by filtering the Reseller Sales table for the fiscal year 2004. We see that the Fiscal Year column is defined in the Date table, but still it is possible to filter the Reseller Sales table using the fiscal year, due to the relationships defined between the tables. The CALCULATE function automatically uses the active relationship between the tables to filter the expression.
FILTER function
The FILTER function is commonly used to filter a table or expression based on the filter conditions. For example:
FILTER(<table>,<filter>) |
In the previous example, to calculate FY04 Sales, we can calculate the same measure using the following DAX formula:
FY04 Sales:=SUMX(FILTER('ResellerSales',RELATED('Date'[FiscalYear])=2004),ResellerSales[SalesAmount]) |
In this formula, we first filter the Reseller Sales table for the fiscal year 2004 and use SUMX to compute the sum of SalesAmount over the filtered Reseller Sales.
RELATED function
The RELATED function is another popular, commonly used function used in calculated columns or measures to perform a lookup to the related table and fetch the column values related by the underlying relationships. The RELATED function uses the underlying table relationships defined during data modeling to perform lookups on the related table.
The RELATED function requires a relationship to exist between the current table and the table with related information. The RELATED function allows users to lookup to the dimension or master tables similar to VLOOKUP for Excel. For example:
RELATED(<column>) |
In this example, to calculate Total Sales for France, we used the RELATED function:
France Sales:=SUMX(FILTER('ResellerSales',RELATED(SalesTerritory[Country])="France"),ResellerSales[SalesAmount]) |
In this formula, we filter the ResellerSales table using the Country column, which belongs to the SalesTerritory. Hence we use the RELATED function, which uses the relationship defined between the ResellerSales table and SalesTerritory table to filter the ResellerSales table for the country France.
ALL function
The ALL function is used to retrieve all values of a column or table ignoring any filters that might have been applied. This function is useful overriding filters and creating calculations on all the rows in a table. For example:
ALL( {<table> | <column>[, <column>[, <column>[,…]]]} ) |
In our data model, let us say we have a requirement to calculate the contribution of each country to the total sales. In order to create this measure, we define the following calculation:
Total Geography Sales:=CALCULATE(SUM(ResellerSales[SalesAmount]),ALL(SalesTerritory[Country])) % Geography Contribution:=[Sales]/[Total Geography Sales] |

- Using the ALL function
Information functions
Information functions are useful functions to check for the existence of some data value, blank, or error. Most information functions return Boolean values, so they are best used with an IF function.
Function | Use |
|---|---|
CONTAINS | Returns TRUE if values exist or are contained in the specified column(s). |
ISBLANK | Returns TRUE if a value is blank and FALSE if the value is not blank. |
ISERROR | Returns TRUE if the value is an error and FALSE if not. |
ISLOGICAL | Returns TRUE if the value is a logical or Boolean value. |
ISNONTEXT | Returns TRUE if the specified value is not text. |
ISNUMBER | Returns TRUE if the specified value is numeric. |
ISTEXT | Returns TRUE if the specified value is text. |
LOOKUPVALUE | Returns the value for the row that meets all criteria specified for search. |
PATH | Returns a delimited text string with the identifiers of all the parents of the current identifier, starting with the oldest and continuing until current. |
PATHCONTAINS | Returns TRUE if the item exists in the specified PATH. |
PATHITEM | Returns the item at the specified position from an evaluation of a PATH function. Positions are evaluated from left to right. |
PATHITEMREVERSE | Returns the item at the specified position from a string resulting from evaluation of a PATH function. Positions are counted backward from right to left. |
PATHLENGTH | Returns the number of parents to the specified item in a given PATH result, including self. |
CONTAINS function
The CONTAINS function returns a Boolean data type (True or False) depending on whether or not the value exists in the specified column. For example:
CONTAINS(<table>, <columnName>, <value>[, <columnName>, <value>]…) |
Consider a scenario where the AdventureWorks management has decided to revise the sales target so that each country should try to meet the sales target of a 20 percent increase, except for the United States. Due to market conditions, management decided to set a target of a10 percent increase for the United States.
To calculate the revised sales target, we use the CONTAINS function as follows:
Revised Sales Target:=IF(CONTAINS(ResellerSales,SalesTerritory[Country],"United States"),[Sales]+0.1*[Sales],[Sales]+0.2*[Sales]) |

- : Using the CONTAINS function
ISBLANK function
The ISBLANK function checks the column value and returns a Boolean value depending on whether the column value is blank.
Blank is a special data type available in the tabular data model that is used to handle nulls. Blank doesn’t mean 0 or a blank text string. Blank is a placeholder used when there is no value. Furthermore, in the tabular data model we do not have nulls, so when the data is imported the nulls are converted to blank values.
The ISBLANK function is useful for checking for blank values within a column. For example:
ISBLANK(<value>) PreviousSales:=CALCULATE([Sales],PARALLELPERIOD('Date'[FullDateAlternateKey],-1,YEAR)) YoY:=[Sales]-[PreviousSales] YoY %:=IF(ISBLANK([Sales]),BLANK(),IF(ISBLANK([PreviousSales]),1,[YoY]/[PreviousSales])) |

- Using the ISBLANK function in a data model
In this example, we use the ISBLANK function to test whether the current year’s sales are blank, and if they are blank, a blank value is displayed. Further, if the current year’s sales are not blank, we check to see if the previous year’s sales are blank. If they are, we represent a 100-percent increase in sales; otherwise we calculate the percentage growth over the previous year’s sales.
Similarly, we have the ISTEXT, ISNONTEXT, ISERROR, and ISLOGICAL functions which are used to test the value of the column and return Boolean values.
PATH functions
PATH functions are specifically designed to address parent–child dimensions. Unlike the multidimensional model, which automatically detects and creates a parent–child hierarchy, the tabular data model doesn’t support the creation of a parent–child hierarchy out of the box.
In our data model, we have an employee table that has a parent–child relationship in which each row represents an employee who has a manager and the manager in turn is an employee in the same table.
First, we create a calculated column in the Employee table using the PATH function to determine the path of each employee to its parent.
=PATH(Employee[EmployeeKey],Employee[ParentEmployeeKey]) |

- Using the PATH function
As you can see, the column now contains the complete path of EmployeeKey from bottom to top stored as a single string value.
Now, for each level in the parent–child relationship we want to create a column. We use the DAX function PathItem for each calculated column to get the key of a specific level. To get the first level of the path, we use the following function.
=PathItem([Path],1,1) |
To get the second level, we use the following function.
=PathItem([Path],2,1) |
The output of the PathItem function will be EmployeeKey of the manager; however, we need the name of the manager, so we use the LOOKUPVALUE function to look it up as follows.
=LOOKUPVALUE(Employee[Name], Employee[EmployeeKey],PATHITEM([Path],1,1)) |
We define the calculated column for each level of the hierarchy using the previous LOOKUPVALUE function to form a flattened hierarchy as shown in the following figure.

- Using PathItem and LOOKUPVALUE to list hierarchy levels
Next, we create an Employees hierarchy by switching to the diagram view:

- Creating an Employees hierarchy
Now, we browse the hierarchy in Excel:

- Employees hierarchy in Excel
The flaws with each approach for creating a parent–child hierarchy are:
- The number of levels in the parent-child hierarchy should be known in advance so that we can create the calculated column for each level.
- If we have a ragged hierarchy, some levels are blank—hence blank values in the hierarchy in Figure 67. However, we can handle blank values by using the ISBLANK function.
This approach to creating a parent–child hierarchy using Path functions references the following blog by Kasper de Jonge, who is a Microsoft program manager: http://www.powerpivotblog.nl/powerpivot-denali-parent-child-using-dax/
Logical functions
Logical functions are useful in checking, error handling, and performing logical AND/OR operations. The following table lists the logical functions supported by DAX.
Function | Use |
|---|---|
AND | Evaluates whether both arguments are true and returns either TRUE or FALSE. |
FALSE | Returns FALSE. |
IF | Evaluates the first argument as a logical test and returns one value if the condition is TRUE and another value if the condition is FALSE. |
IFERROR | Evaluates an expression and returns a specified value if the expression returns an error. If the value does not return an error, then the value is returned. |
NOT | Changes the value of logical TRUE or FALSE. |
OR | Evaluates whether one of two arguments is true and returns TRUE if one is true or FALSE if both are false. |
SWITCH | Evaluates an expression against a list of values and returns one possible expression. This function is very similar to a SWITCH function in C++ or C#. |
TRUE | Returns TRUE. |
Most of the functions listed in this category are self-explanatory and commonly used in other programming languages.
IFERROR is a special function used for error handling in DAX, which we will discuss in more detail. IFERROR is actually a combination of two functions, IF and ISERROR. Since they are commonly used in tandem for error handling, the SSAS product team decided to have a dedicated IFERROR function. For example:
IFERROR(value, value_if_error) |
In a previous example, to calculate year-over-year (YoY) percentages, we used the ISBLANK function to handle blank values from the previous year. However, we can also use the IFERROR function to achieve similar results, as shown in the following example.
YoY %:=IF(ISBLANK([Sales]),BLANK(),IFERROR([YoY]/[PreviousSales],BLANK())) |
Mathematical functions
Since DAX is an analytical query language, it has to support mathematical functions useful for analytics and reporting. DAX supports the following mathematical functions.
Function | Use |
|---|---|
ABS | Returns the absolute value of a numeric argument. |
CEILING | Rounds a number up to the nearest integer value or significant multiple. |
CURRENCY | Evaluates the value passed as an argument and returns the result as currency. |
EXP | Returns the value of e (2.71828182845904) raised to the power specified. |
FACT | Returns the factorial of a numeric value. |
FLOOR | Rounds a number down to the nearest significant multiple. |
INT | Rounds a numeric value down to the nearest integer value. |
ISO.CEILING | Rounds a number up to the nearest integer value or significant multiple. |
LN | Returns the natural logarithm of a numeric value. |
LOG | Returns the logarithm of a number to the base you specify. |
LOG10 | Returns the base-10 logarithm of a number. |
MROUND | Returns a number rounded to the desired multiple. |
PI | Returns the value of Pi, 3.14159265358979, accurate to 15 digits. |
POWER | Returns the result of a number raised to a power. |
QUOTIENT | Performs division and returns only the integer portion of the division result. |
RAND | Returns a random number greater than or equal to 0 and less than 1, evenly distributed. |
RANDBETWEEN | Returns a random number in the range between two numbers you specify. |
ROUND | Rounds a number to the specified number of digits. |
ROUNDDOWN | Rounds a numeric value down. |
ROUNDUP | Rounds a numeric value up. |
SIGN | Determines the sign of a numeric value and returns 1 for positive, 0 for zero, or -1 for negative values. |
SQRT | Returns the square root of a numeric value. |
SUM | Returns the sum of all numbers in a column. |
SUMX | Returns the sum of an expression evaluated for each row in a table. |
TRUNC | Truncates a number to an integer by removing the decimal portion of the number. |
I believe the functions are pretty self-explanatory and don’t need detailed elaboration. If necessary, we can refer to online documentation for syntax of the functions and put them to use.
Statistical functions
DAX supports the following list of statistical functions. Note that there is some overlap between aggregate and statistical functions (SUMX, COUNT, AVERAGE, etc.).
Function | Use |
|---|---|
ADDCOLUMNS | Adds calculated columns to a table or table expression. |
AVERAGE | Returns the arithmetic mean of the numbers in a column. |
AVERAGEA | Returns the arithmetic mean of the numbers in a column, but handles non-numeric values |
AVERAGEX | Calculates the arithmetic mean of a set of expressions over a table. |
COUNT | Counts the number of cells in a column that contain numbers. |
COUNTA | Counts the number of cells in a column that are not empty, regardless of data type. |
COUNTAX | Counts the number of rows in a table where the specified expression results in a nonblank value. |
COUNTBLANK | Counts the number of blank cells in a column. |
COUNTROWS | Counts the number of rows in the specified table or tabular expression. |
COUNTX | Counts the number of rows that evaluate to a number. |
CROSSJOIN | Returns a table that contains the Cartesian product of all rows from all tables in the arguments. |
DISTINCTCOUNT | Counts the number of distinct cells in a column of numbers. |
GENERATE | Returns a table with the Cartesian product between each row in table1 and the table that results from evaluating table2. |
GENERATEALL | Returns a table with the Cartesian product between each row in table1 and the table that results from evaluating table2. |
MAX | Returns the largest numeric value contained in a column. |
MAXA | Returns the largest value in a column, including Boolean and blank values. |
MAXX | Evaluates an expression for each row of a table and returns the largest numeric value. |
MIN | Returns the smallest numeric value in a column. |
MINA | Returns the smallest numeric value in a column including Boolean and blank values. |
MINX | Returns the smallest numeric value after evaluating an expression for each row of a table. |
RANK.EQ | Returns the ranking of a number in a list of numbers. |
RANKX | Returns the ranking of a number in a list of numbers for each row in the table argument. |
ROW | Returns a table consisting of a single row using expressions for each column. |
SAMPLE | Returns a sample of rows from a specified table, with the number of rows determined by the user. |
STDEV.P | Returns the population standard deviation. |
STDEV.S | Returns the sample standard deviation. |
STDEVX.P | Returns the population standard deviation. |
STDEVX.S | Returns the sample standard deviation. |
SUMMARIZE | Returns a summary table. |
TOPN | Returns the top N rows of a table where N is a numeric value specified by the user. |
VAR.P | Returns the variance for a sample population. |
VAR.S | Returns the variance estimate for a population. |
VARX.P | Returns the variance estimate for a population. |
VARX.S | Returns the variance for a sample population. |
Some of the statistical functions (such as GENERATE, SUMMARIZE, CROSSJOIN, and TOPN) are useful functions when we use DAX as a query language in client tools. In this section we will discuss RANK functions.
RANKX function
The RANKX function, as the name suggests, is used to rank a column based on an expression or measure. For example:
RANKX(<table>, <expression>[, <value>[, <order>[, <ties>]]]) |
Consider a scenario where AdventureWorks wishes to rank the products based on their demand and order quantities for the product. To achieve this, we first define a calculated measure, Orders, to capture the order quantity.
Orders:=SUM(ResellerSales[OrderQuantity]) |
Next we use the RANKX function in the Products table to define a calculated column, which ranks the products on the basis of the measure Orders.
=RANKX(Product,[Orders]) |

- Using the RANKX function
Text functions
Text functions are similar to string manipulation functions. These are the text functions available in the DAX query reference:
Function | Use |
|---|---|
REPLACE | Replaces part of a text string with different text. |
REPT | Repeats the text the number of times specified in the parameter. |
RIGHT | Returns the specified number of characters from the end of a string. |
SEARCH | Returns the number of the character at which a specific character or text string is first found, reading left to right. Search is case-insensitive and accent sensitive. |
SUBSTITUTE | Replaces existing text with new text. |
TRIM | Removes leading and trailing spaces from a string. |
UPPER | Converts a string to upper case. |
VALUE | Converts a text representation of a numeric value to a number. |
BLANK | Returns a BLANK value. |
CONCATENATE | Concatenates two text strings. |
EXACT | Compares two text strings and returns TRUE if they are exactly the same, including case. |
FIND | Returns the starting position of one text string within another text string. |
FIXED | Rounds a number to the specified number of decimals and returns the result as text. |
FORMAT | Converts a value to text. |
LEFT | Returns the specified number of characters from the start of a text string. |
LEN | Returns the number of characters in a string of text. |
LOWER | Converts a text string to lower case. |
MID | Returns a string of characters based on a starting position and length. |
Most text functions are self-explanatory and pretty straightforward, so we will not discuss them in detail. In fact we have already used FORMAT and CONCATENATE functions in some previous examples.
Time intelligence functions
As discussed previously, date and time are conformed dimensions in the data warehouse as most analysis is performed across the time axis, such as comparing measures like YoY, QoQ, and MoM, and calculating YTD, QTD, and MTD. Time intelligence functions are available to facilitate such calculations.
Function | Use |
|---|---|
CLOSINGBALANCEMONTH CLOSINGBALANCEQUARTER CLOSINGBALANCEYEAR | Calculates a value at the calendar end of the given period. |
OPENINGBALANCEMONTH OPENINGBALANCEQUARTER OPENINGBALANCEYEAR | Calculates a value at the calendar end of the period prior to the given period. |
TOTALMTD TOTALYTD TOTALQTD | Calculates a value over the interval that starts at the first day of the period and ends at the latest date in the specified date column. |
DATEADD | Returns a table that contains a column of dates, shifted either forward or backward in time. |
DATESBETWEEN | Returns a table that contains a column of dates that begins with the start_date and continues until the end_date. |
DATESINPERIOD | Returns a table that contains a column of dates that begins with the start_date and continues for the specified number_of_intervals. |
DATESMDT | Returns a table that contains a column of the dates for the given period in the current context. |
ENDOFMONTH | Returns the last date of the given period in the current context. |
NEXTDAY | Returns a one column table containing all dates in the next period, based on the date specified in the current context. |
FIRSTDATE | Returns the first date from the specified column of dates based on the current context. |
FIRSTNONBLANK | Returns the first value in the column filtered by the current context where the expression is not blank. |
LASTDATE | Returns the last date in the current context for the specified column of dates. |
LASTNONBLANK | Returns the last value in the column filtered by the current context where the expression is not blank. |
PARALLELPERIOD | Returns a table that contains a column of dates that represents a period parallel to the dates in the specified dates column, in the current context, with the dates shifted a number of intervals either forward in time or back in time. |
PREVIOUSDAY | Returns a one column table containing all dates in the previous period, based on the date specified in the current context. |
SAMEPERIODLASTYEAR | Returns a table that contains a column of dates shifted one year back in time from the dates in the specified dates column using the current context. |
STARTOFMONTH | Returns the first date of the specified period based on the current context. |
In order to use time intelligence functions in our data model, we need to have a table marked as a date table and identify one of the columns of that table as a unique identifier, which should be of the date data type.
In our data model, we have a Date table defined which can be marked as a date table, and the column FullDateAlternateKey which is a unique identifier for the table and is of the date data type. In our data model, we mark the Date table by selecting the table and clicking Table > Date > Mark As Date Table as shown in the following figure.

- Setting up a table to use time intelligence functions
Next, we click the Date Table Settings option in the same menu, and select the FullDateAlternateKey unique identifier column in the Date field.

- Marking a date table
Now that we have marked a date table, we use time intelligence functions to define calculations in our data model.
TotalYTD, TotalQTD, and TotalMTD functions
TotalYTD, TotalQTD, and TotalMTD are functions commonly used in financial analysis to evaluate an expression from the start of the year to the current date, from the start of the quarter to the current date, and from the start of the month to the current date. For example:
TOTALYTD(<expression>,<dates>[,<filter>][,<year_end_date>]) TOTALQTD(<expression>,<dates>[,<filter>]) |
In our data model, we define the YTD Sales and QTD Sales measures as follows:
YTD Sales:=TOTALYTD(SUM(‘Reseller Sales’[SalesAmount]),'Date'[FullDateAlternateKey],ALL('Date'),"6/30") QTD Sales:=TOTALQTD(SUM(‘Reseller Sales’[SalesAmount]), 'Date'[FullDateAlternateKey],ALL('Date')) |

- Using the TotalYTD and TotalQTD functions
PREVIOUSYEAR, PREVIOUSQUARTER functions
PREVIOUSDAY, PREVIOUSMONTH, PREVIOUSQUARTER, and PREVIOUSYEAR functions are commonly used functions in financial analysis for comparing the current measure value with the previous day, month, quarter, or year. For example:
PREVIOUSYEAR(<dates>[,<year_end_date>]) PREVIOUSQUARTER(<dates>) |
In our data model, we can define the measures PreviousYearSales and PreviousQuarterSales, which calculate the sales for previous years and previous quarters using the following DAX formula:
PreviouYearsSales:=CALCULATE([Sales],PreviousYear('Date'[FullDateAlternateKey])) PreviousQuarterSales:=CALCULATE([Sales],PREVIOUSQUARTER('Date'[FullDateAlternateKey])) |

- Using PREVIOUSYEAR and PREVIOUSQUARTER Functions
SAMEPERIODLASTYEAR function
The SAMEPERIODLASTYEAR function returns a table that contains a column of dates shifted one year back in time from the dates in the specified date column, in the current context.
The SAMEPERIODLASTYEAR functionality is also possible by using the PARALLELPERIOD function as follows:
PARALLELPERIOD(dates,-1,year) |
For example:
SAMEPERIODLASTYEAR(<dates>) |
In our data model, we previously defined the calculated measure PreviousSales, which calculates the sales for THE same period last year using the PARALLELPERIOD function as follows:
PreviousSales:=CALCULATE([Sales],PARALLELPERIOD('Date'[FullDateAlternateKey],-1,YEAR)) |
We can also rewrite this measure using the SAMEPERIODLASTYEAR function to achieve the same result:
PreviousSales:=CALCULATE([Sales],SAMEPERIODLASTYEAR('Date'[FullDateAlternateKey])) |
Now that we are more familiar with DAX functions, in the next section we will see how we can use some of these functions for reporting.
DAX as a query language
In some of the client reporting tools such as SSRS, we use DAX as a query language to define the dataset to fetch the data from the tabular data model cube. When we use DAX as a query language, we use some of the same functions we discussed earlier, which returns a tabular dataset.
When DAX is used as a query language, we use the following syntax:
DEFINE { MEASURE <table>[<col>] = <expression> }] EVALUATE <Table Expression> [ORDER BY {<expression> [{ASC | DESC}]} [, …] [START AT {<value>|<parameter>} [, …]] ] |
DAX as a query language always starts with the EVALUATE keyword followed by an expression, which returns a table. The DEFINE keyword is used to define a calculated measure within the scope of the query.
In order to use DAX as a query language, we use SQL Server Management Studio to connect the tabular Analysis Services cube and click on the New MDX Query window.
The same MDX query window is also used to execute DAX queries against tabular model cubes as shown in Figure 73.
For example, the simplest DAX query would be:
EVALUATE 'SalesTerritory' |

- Using DAX as a query language
This query returns SalesTerritory as the output. If the output needs to be sorted by country, we can rewrite the query as:
EVALUATE 'SalesTerritory' ORDER BY 'SalesTerritory'[Country] |
Applying filters to a DAX query
If we need to evaluate the sales for the fiscal year 2004 for the United States, we use the FILTER function to filter the ResellerSales table for the Country United States and FiscalYear 2004. The resulting DAX query is:
EVALUATE FILTER( FILTER('ResellerSales', RELATED('SalesTerritory'[Country])="United States"), RELATED('Date'[FiscalYear])=2004 ) |
Adding columns to query output in a DAX query
Consider a report where we need all the products in the AdventureWorks catalog along with their max quantities ordered to date. We can use the ADDCOLUMNS function to add a calculated column that computes the max order quantity and adds it to the product table. The resulting DAX query is:
EVALUATE ADDCOLUMNS('Product', "Max Quantities Ordered",CALCULATE(MAX('ResellerSales'[OrderQuantity]),ALL(Product[Product])) ) ORDER BY [Max Quantities Ordered] desc |
Aggregating and grouping in a DAX query
Consider a report where we need the aggregated Sales value for each Product Category. This can be easily achieved in a DAX query by using the SUMMARIZE function as follows:
EVALUATE SUMMARIZE( 'Product', 'Product'[Product Category], "Sales",FORMAT(SUM(ResellerSales[SalesAmount]),"CURRENCY") ) ORDER BY [Sales] desc |

- Using a DAX query to aggregate values
If we want to compute total sales as well, we can use the SUMMARIZE function along with ROLLUP in the DAX query:
EVALUATE SUMMARIZE ( 'Product', ROLLUP('Product'[Product Category]), "Sales",FORMAT(SUM(ResellerSales[SalesAmount]),"CURRENCY") ) ORDER BY [Sales] asc |
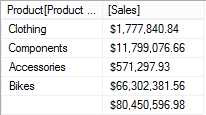
- Using a DAX query to aggregate values
Using CROSSJOIN in a DAX query
Consider a report where we need to compute the sales for each country, for each fiscal year. We can use the CROSSJOIN function to achieve this as shown in the following DAX query:
EVALUATE FILTER( ADDCOLUMNS( CROSSJOIN( ALL('Date'[FiscalYear]), ALL('SalesTerritory'[Country]) ), "Sales",FORMAT(ResellerSales[Sales],"CURRENCY") ), ResellerSales[Sales]>0 ) |

- Using CROSSJOIN in a DAX query
Using TOPN in a DAX query
Consider a report where we need to identify the top three products that are in demand. To achieve this, we will use the TOPN function and the Demand Rank calculated column defined previously, which calculates the rank for each product based on the total order quantities sold to date.
EVALUATE TOPN(3,Product,Product[Demand Rank],1) ORDER BY Product[Demand Rank] |

- Using the TOPN function in a DAX query
Define measures in a DAX query
In the previous example where we designed a DAX query to calculate the max quantities sold for each product to date, we can rewrite the query by defining the measure as shown in the following sample.
DEFINE MEASURE 'Product'[Max Quantities Ordered]=CALCULATE(MAX('ResellerSales'[OrderQuantity]),ALL(Product[Product])) EVALUATE ADDCOLUMNS('Product', "Max Quantities Ordered",'Product'[Max Quantities Ordered] ) ORDER BY [Max Quantities Ordered] desc |
Defining query-scoped measures simplifies the query to a large extent. For instance, in the previous query we first define a calculated measure to compute the max order quantity sold for all products. When this measure is used within the ADDCOLUMNS function, the measure is evaluated in row context for each row of the product table, which gives the max order quantity for each product.
Using the GENERATE function in a DAX query
In the previous example, we calculated the top three products in demand based on the total order quantities sold using TOPN. Now, let us say we need to calculate the top three products in demand for each country to identify the most popular products in each country.
To do this, we need to iterate the same TOPN calculation for each country. This is possible using the GENERATE function in DAX as follows.
DEFINE MEASURE 'Product'[Max Quantities Ordered]=IF(ISBLANK(MAX('ResellerSales'[OrderQuantity])),0,MAX('ResellerSales'[OrderQuantity])) EVALUATE GENERATE ( VALUES('SalesTerritory'[Country]), ADDCOLUMNS( TOPN(3,VALUES('Product'[Product]),'Product'[Max Quantities Ordered]), "Max Quantities Ordered",'Product'[Max Quantities Ordered] ) ) |
In this DAX query, we repeat the TOPN calculation which calculates the top three products based on the max order quantities sold for each country using the GENERATE function. The resulting output of the query is shown in the following figure:

- Using the GENERATE function in a DAX query
These examples should give us enough exposure to get started with DAX. Like with any other query language, we can achieve expertise in DAX with more practice.
Summary
In this chapter, we learned how to define calculated columns and measures using the DAX language. In the next chapter, we will discuss how to prepare our data model for deployment and deploying the data model for reporting and analytics.
- 1800+ high-performance UI components.
- Includes popular controls such as Grid, Chart, Scheduler, and more.
- 24x5 unlimited support by developers.