- Home
- Forum
- Big Data Platform
- Unability To Start Services On hadoop Nodes
Unability To Start Services On hadoop Nodes
what will be the reason
here is the log file that contains files for today (which is stopping date)
can you help me please iam not able to restart the nodes
192.168.1.175 namenode
192.168.1.171 Secondary name node
192.168.1.173 first data node
192.168.1.172 data node
192.168.1.174 data node
Attachment: Logs_a87e270d.rar
https://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
The JournalNode daemon is relatively lightweight, so these daemons may reasonably be collocated on machines with other Hadoop daemons,
for example NameNodes, the JobTracker, or the YARN ResourceManager. Note: There must be at least 3 JournalNode daemons,
since edit log modifications must be written to a majority of JNs. This will allow the system to tolerate the failure of a single machine.
You may also run more than 3 JournalNodes, but in order to actually increase the number of failures the system can tolerate,
you should run an odd number of JNs, (i.e. 3, 5, 7, etc.). Note that when running with N JournalNodes,
the system can tolerate at most (N - 1) / 2 failures and continue to function normally.
my cluster consists of NameNode,Secondary Node,DataNode1,DataNode,DataNode3
and three Journal Nodes which are installed by default on namenode,secondary node and first data node
my question is which scenario is right
and 2 possible failures of data nodes(which doesn't have the journal node) becuase i have three data nodes and replication factor that covers all data nodes )
and what is the meaning of failuer when it happens (is it Unabilty to continue working )
or it is unability to restart the whole cluster again when all nodes reworking again
were stopped together
but my question is: Can Syncfusion Cluster Restart Services Again after this Senario
or i should readd namenode , secondary name node ,another data node again to this cluster (i mean at least three journal nodes )
and consider old ones to be as nothing ?
| my question is which scenario is right is my cluster going to tolerate one (name node or secondary name node )failure (3-1)/2=1 possible failure and 2 possible failures of data nodes(which doesn't have the journal node) becuase i have three data nodes and replication factor that covers all data nodes ) or my cluster tolerate one failure only even if is data node failure or (NameNode Or Secondary NameNode Faiuler) | Your first statement is correct. Your 5-node cluster can tolerate and work properly even though 1 name node and 2 data nodes have failed. In this case 1 active name node and 1 working data node will be available in the cluster. |
| what is the meaning of failuer when it happens (is it Unabilty to continue working ) | Beyond tolerate threshold (one name node failure or two data node failure), you will have only one active name node and one working data node, then the cluster will fail totally in one of following cases happen, 1. If working data node failed, existing data will be lost. Still you can add new data nodes and start working with new data. 2. If active name node failed, the cluster will become unusable and down until we restart the all the services. |
| Can Syncfusion Cluster Restart Services Again after this Senario | Yes. If all the nodes are restarted properly, we can regain the access of the cluster without any data loss. |
| it is unability to restart the whole cluster again when all nodes reworking again | If all the cluster nodes machine and Big Data Agent are restarted and running properly, we can restart the whole cluster using Cluster Manager. To achieve this, please do the following steps, 1. In Cluster Manager, open Management page where the status of all services is displayed. The following screenshot state that installer agent service is running in all nodes and cluster's services are in dead state, 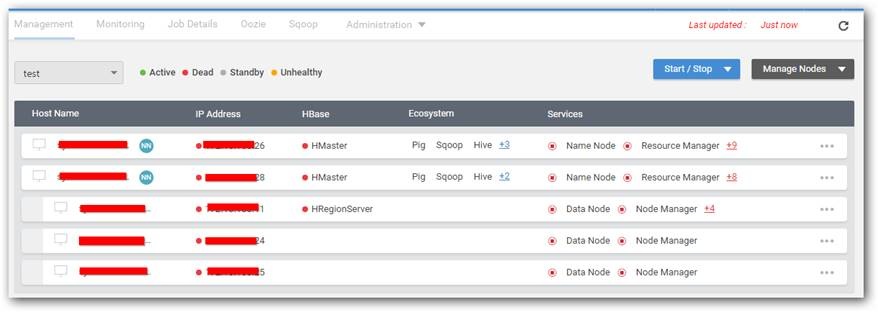 2. Click Start all Services. 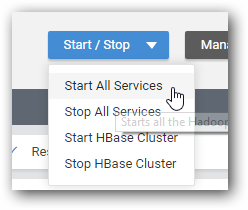 3. You can see the status like below, once the cluster services are properly turned up. 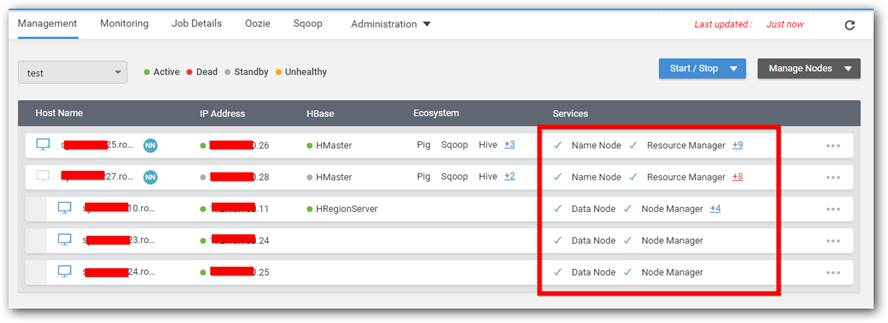 |
| or i should readd namenode , secondary name node ,another data node again to this cluster (i mean at least three journal nodes ) and consider old ones to be as nothing ? | It is not required to add all the nodes again, if cluster is turned up with Cluster Manager. |
|
My Question |
Your Answer |
Comment |
|
it is un ability to restart the whole cluster again when all nodes reworking again |
If all the cluster nodes machine and Big Data Agent are restarted and running properly, we can restart the whole cluster using Cluster Manager. |
All cluster nodes machines and big data agents are restarted and running properly And of course, i tried to start all the services and the result was NameNode ,secondary name node and first data node appears as dead but datanode2 and datanode3 (data nodes that are not in default high availability group ,i mean not with name node and secondary name node) appears as active at first then after some time they appears as dead of course because of name node and secondary name node dead state
|
|
or i should read name node , secondary name node ,another data node again to this cluster (i mean at least three journal nodes ) and consider old ones to be as nothing ?
|
It is not required to add all the nodes again, if cluster is turned up with Cluster Manager. |
If it is not turned up, should I remove name node ,secondary name node and first data node and then readd them again
I attached the log can you verify it please and tell me if iam able to turn up the cluster again before trying this scenario Because this scenario of course will loss one data node And the data contained in ,log files in name node And what will be other files? |
|
Restarting all vms together |
|
I want to mention that after restarting all vms together The state I mentioned at first, big data agent got corrupted in name node and I wasn’t able to stop its service or restart it from services. MSc so I uninstalled it and reinstall it and every thing was ok ,but why it is getting corrupted |
We considered this “Unability to start services on Hadoop Nodes” as a custom query and a support incident has been created under your account to track the status of this requirement. Please log on to our support website to check for further updates.
https://www.syncfusion.com/account/login?ReturnUrl=/support/directtrac/incidents
Regards,
Dinesh Kumar P
- 4 Replies
- 2 Participants
-
SH Shadi
- Dec 14, 2016 02:00 PM UTC
- Dec 19, 2016 01:15 PM UTC
