Smart Data Extraction for .NET
- High-performance C# engine for PDFs and scanned images.
- Extract tables, forms, and document structure.
- Confidence scores for extracted fields and table cells.
Trusted by the world’s leading companies

Overview
The Syncfusion Smart Data Extractor is a high-performance C# library for .NET that extracts structured information from PDFs and scanned images. Using machine-learning–based layout analysis, it identifies document elements such as tables, form fields, and key content regions by analyzing visual patterns like lines, boxes, labels, and alignment. The library returns structured JSON with confidence scores for each extracted element, enabling reliable indexing, analytics, and automated data processing, and can optionally generate digitally reconstructed PDFs for validation and archival workflows.
High-Performance Data Extraction APIs in .NET
Extract data intelligently from scanned PDFs and images using a high performance set of APIs in .NET. This smart data extraction library uses machine learning based layout analysis to detect tables, extract key information, and identify form fields, delivering structured output in JSON format. It enables you to build scalable, enterprise grade data extraction and automation solutions within your applications.
Smart Extraction
Standard Extraction
Why choose the Syncfusion Smart Data Extractor?
Zero external AI dependencies
The extraction engine runs entirely within your .NET environment without requiring external AI services or cloud APIs. This allows organizations to process documents securely while maintaining full control over data privacy, legal and regulatory compliance, and operational costs.
High performance at scale
The extraction engine is optimized for large-scale document processing, enabling high-throughput extraction for batch workloads and real-time document pipelines. Efficient processing helps reduce operational overhead and improves processing turnaround time.
Fully offline .NET integration
Deploy the library directly within your application or on-premises infrastructure without any external runtime dependencies. This enables fully offline document processing, making it suitable for environments with strict data governance or security requirements.
Configurable extraction
Developers can configure extraction behavior to match different document formats by adjusting parameters such as page range, confidence score, and borderless table detection. These controls help improve extraction relevance and reduce false positives for specific document types.
Structured output formats
Extracted results can be exported as structured JSON for integration with downstream systems, analysis-ready JSON tables, or fillable PDFs that visually represent extracted structures for review and validation workflows.
Confidence-based validation
Machine learning models combined with layout-based analysis help identify document elements more reliably. Per-field and per-cell confidence scores allow applications to automate validation while minimizing manual correction.
Extract data from PDF
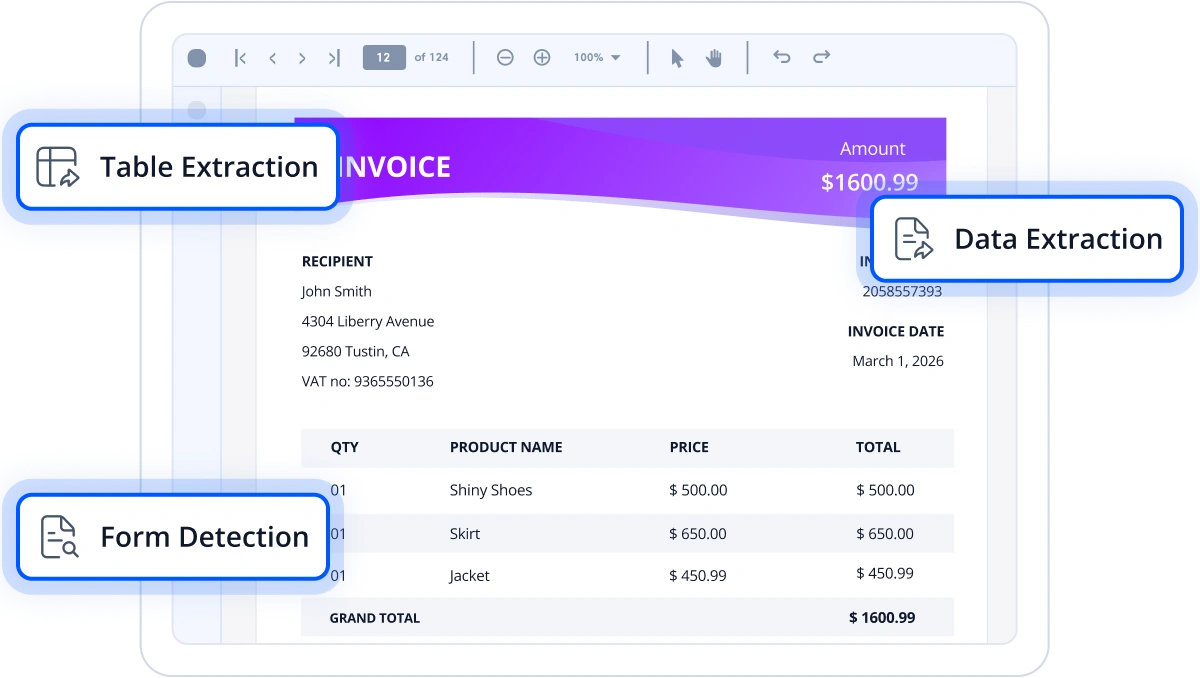
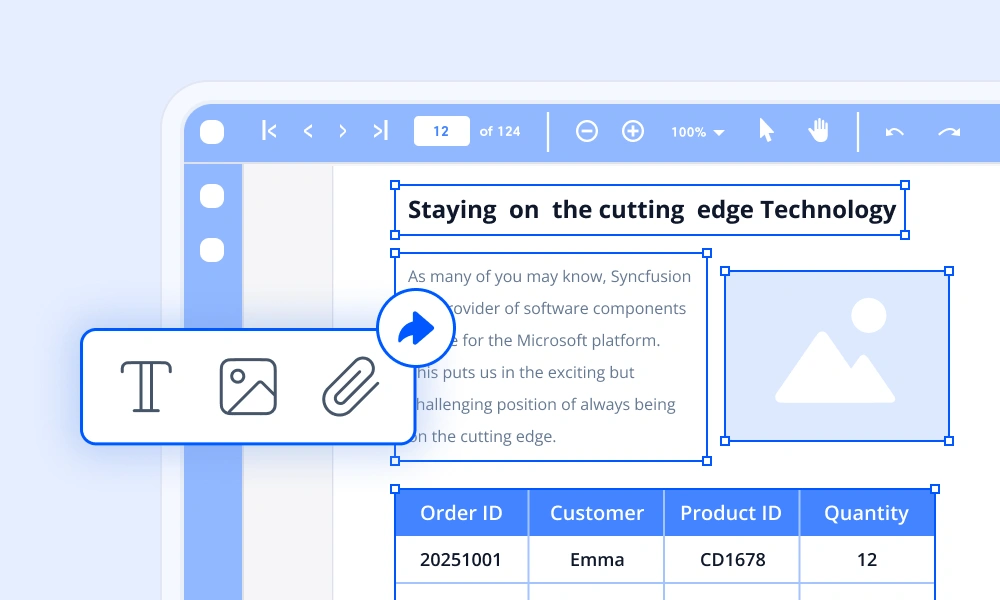
The library extracts document structures such as hierarchies, text blocks, images, headers, and footers from PDFs and scanned images by analyzing visual layout patterns like lines, boxes, and alignment. It returns structured JSON with per-field confidence scores, enabling reliable indexing, metadata enrichment, and downstream ETL workflows. The engine can also generate digitally reconstructed PDFs to visually validate extracted results in automated processing pipelines.
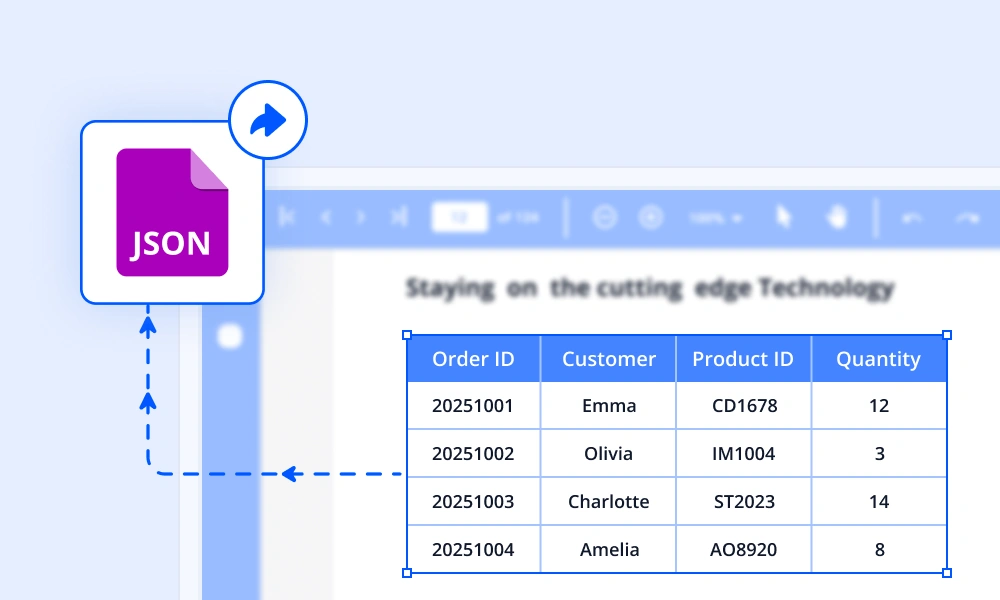
Extract tables from PDFs
Table extraction identifies table regions, header rows, columns, and merged cells in PDFs and scanned documents using layout-aware analysis. Extracted tables are returned as analysis-ready JSON with preserved header relationships and per-cell confidence scores, making them easy to integrate into analytics, reporting, and business intelligence pipelines.
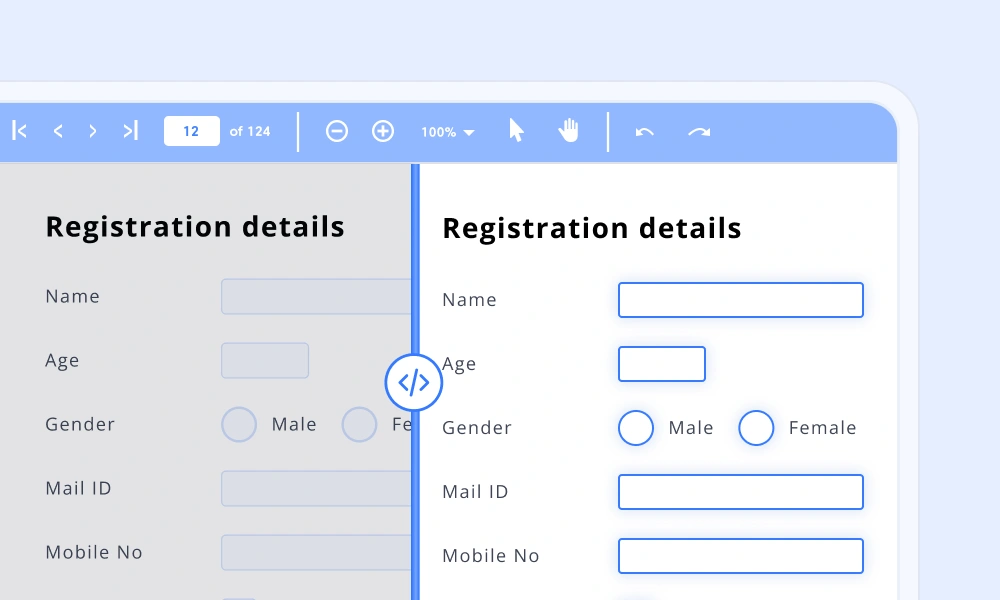
Form recognizer for PDF
Form recognition detects form regions and extracts text fields, checkboxes, radio buttons, and signatures by interpreting visual patterns such as boxes and selection markers. The extracted results are returned as normalized JSON with confidence scores, enabling applications to automatically process form data. It can also generate fillable PDFs for validation and document review workflows.

See Real Success Stories
Developers around the world trust Syncfusion’s Essential Studio to simplify complex projects and speed up delivery. With a vast library of UI controls, powerful SDKs, and reliable support, Essential Studio helps teams build enterprise-ready applications with confidence.
Read Our Customer StoriesIndustry
Software development
75% Cost reduction
50% Faster development
Industry
Utilities (oil and gas)
450+ hours saved
Streamlined processes and hours of development effort saved.
Advanced, flexible features
Empowered users through robust and versatile functionality.
Industry
Software and technology
1000+ of hours saved
Accelerated development with enterprise-ready UI components.
Efficient file management
Streamlined workflows with document libraries without building them from scratch.
Industry
Software and technology
2 Years of delay avoided
Two years of delays prevented with proactive planning.
On-time delivery
Projects delivered on schedule using trusted controls.
Industry
IT services and IT consulting
Improved performance
Large datasets handled with easy customization and quick debugging.
Highly customizable
Plug-and-play controls with quick template integration.
Industry
Professional services
Instant access
Quick availability of features and resources.
Reduced dependencies
Fewer dependencies for faster development.
Rated by users across the globe
Syncfusion Smart Data Extractor resources





Awards
Greatness—it’s one thing to say you have it, but it means more when others recognize it. Syncfusion® is proud to hold the following industry awards.

