Syncfusion React Pivot Table — Enterprise Architecture Overview
Enterprise pivot tables are foundational components in modern business applications, enabling interactive aggregation, slicing, and drill-down of business data through dynamic transformation into a multidimensional analytical view. As application complexity increases, pivot tables must continue to deliver high performance, secure data handling, flexible integration, and a consistent user experience across large and frequently changing hierarchies.
The Syncfusion React Pivot Table is designed for these enterprise requirements. It provides a scalable rendering architecture with virtualization and flexible integration patterns for local and remote data sources. It supports advanced interaction scenarios, including sorting, filtering, drill down, drillthrough, calculated fields, conditional formatting, aggregation, and real-time refreshing. The component also includes built-in accessibility, localization, responsive layout behavior, export capabilities, and more to help organizations meet enterprise usability, compliance, and reporting requirements.
The following sections document the Pivot Table’s architecture, supported integration patterns, scalability characteristics, and documented behavioral characteristics to assist decision-makers in evaluating the component for enterprise adoption.
AI and extensibility
The Pivot Table supports custom cell renderers, toolbar extensions, and event hooks that allow AI-assisted features, such as AI-assisted pivot analysis and smart pivot, to be integrated as application-layer extensions. The Pivot Table itself does not ship an AI runtime or call any external AI service; AI capabilities are wired in by the application and routed through the application's own back end or model endpoints. AI features inherit the same data-flow boundaries as the Pivot Table.
Typical enterprise usage scenarios
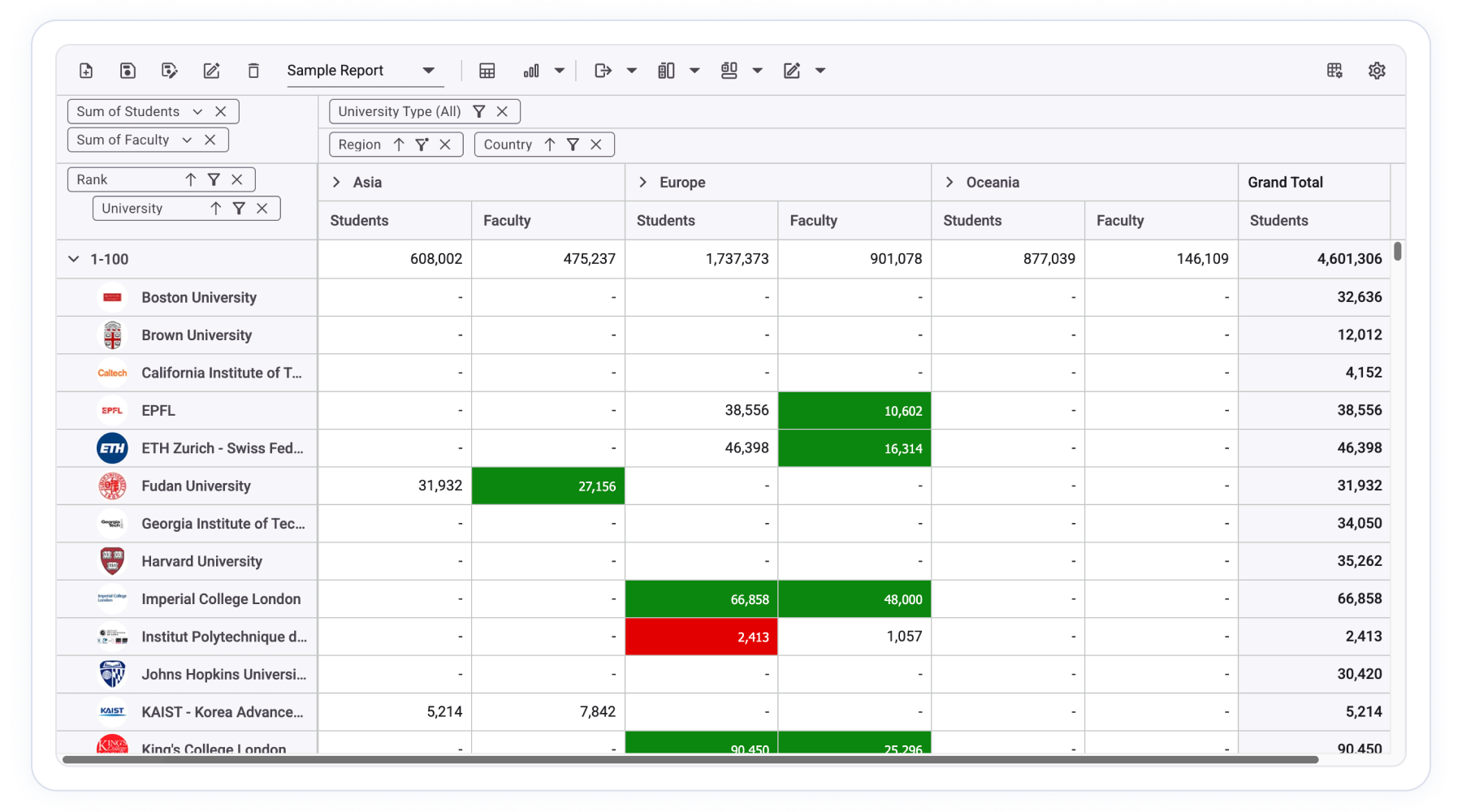
The Pivot Table is commonly used in applications where multidimensional data must be aggregated, sliced, and analyzed interactively from large datasets.
Examples include:
- Financial planning and analysis (FP&A) platforms enabling variance analysis across cost centers, time periods, and business units.
- Sales and revenue operations dashboards aggregating performance metrics by region, product, and time dimension.
- Healthcare reporting systems summarizing patient and clinical data across multiple categorical dimensions.
- Retail and e-commerce analytics tools presenting sell-through, inventory, and margin data across SKU and store hierarchies.
- Enterprise business intelligence portals where business users explore and drill into operational KPIs without engineering support.
In these environments, the Pivot Table acts as both a multidimensional data visualization layer and an interactive analysis interface, requiring predictable performance and reliable interaction behavior under heavy workloads. Each scenario places different demands on the Pivot Table: FP&A platforms require server-side aggregation for datasets that exceed browser memory limits; sales dashboards require drill down and drillthrough with low interaction latency; BI portals require field list customization and conditional formatting to surface exceptions at scale.
Architectural capabilities
The Syncfusion React Pivot Table provides a compact set of architectural capabilities for enterprise applications:
- Viewport-based rendering (row and column virtualization) to keep the DOM footprint predictable across wide and tall pivot layouts with large numbers of members.
- Server-side engine mode to delegate aggregation, sorting, filtering, and drill operations entirely to the back end, enabling pivot analysis on datasets that cannot be loaded into the browser.
- Virtual scrolling support for both row and column axes, ensuring consistent rendering performance as pivot dimensions and the number of members grow.
- OLAP (Microsoft SSAS) connectivity via XMLA protocol, enabling direct binding to enterprise cube data sources alongside flat JSON, CSV and remote data-binding options.
- Drill-down and drillthrough support, allowing users to expand member hierarchies and access underlying, record-level data within the same component.
- Conditional formatting and KPI indicators to surface threshold breaches and performance exceptions directly within the pivot layout.
- Flexible field list UI for end-user-driven field arrangement, filter application, and aggregation-type selection without code changes.
- Calculated fields support for custom measure definitions applied at the pivot engine level, enabling derived metrics without back-end schema changes.
- Accessibility and internationalization support (including WCAG compliance, ARIA roles, RTL).
- Template-based rendering for domain-specific UI in cells, headers, and toolbar items.
- Built-in exporting (Excel and PDF) and server-side exporting options for very large pivot datasets.
- Integration patterns for REST/OData, XMLA, and flat JSON sources; compatible with Redux/RTK, Zustand, MobX, and TanStack Query. The Pivot Table is a controlled component driven by props, with no internal global state.